Artificial Intelligence
Mengenal Large Language Model LLM
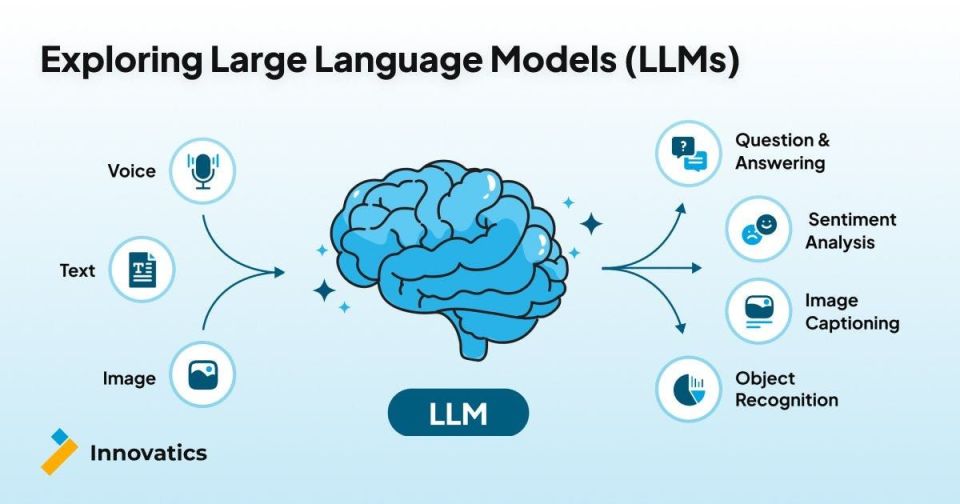
Siapa sih yang nggak lagi ngomongin soal LLM atau Large Language Model sekarang? Teknologi AI yang lagi nge-hits ini kayaknya ada di mana-mana, dari asisten virtual di HP sampai chatbot yang bisa ngobrol lancar banget. Tapi, sebenarnya apa itu LLM? Gimana sih cara kerjanya sampai bisa sepintar itu? Yuk, kita kupas tuntas bareng!
LLM itu kayak perpustakaan raksasa di dalam komputer, tapi bukannya buku fisik, isinya adalah triliunan data teks dan kode. Bayangin aja ada "orang" yang udah baca semua buku di dunia, semua artikel di internet, semua postingan blog, bahkan semua percakapan online. Nah, dari situ, "orang" ini belajar pola, tata bahasa, konteks, dan bahkan cara mikir manusia. Makanya, dia bisa ngerti dan ngasih respon yang kedengeran natural banget, kayak ngobrol sama temen.
LLM: AI Canggih yang Ngerti Bahasa Kita Banget
Jadi, intinya Large Language Model (LLM) itu sebuah kategori model pembelajaran mendalam (deep learning) yang dilatih pakai data dalam jumlah sangat besar. Ini bukan sekadar banyak, tapi super duper banyak. Karena saking banyaknya data yang dia "lahap", LLM jadi punya kemampuan luar biasa buat memahami dan menghasilkan bahasa alami manusia, plus jenis konten lainnya.
Kalau diibaratkan, LLM itu kayak orang yang rajin banget datang ke perpustakaan, buka buku satu per satu, dan nyerap semua ilmunya. Bedanya, perpustakaan digital ini ukurannya astronomis, jauh melebihi perpustakaan fisik mana pun yang bisa kita bayangkan.
Definisi Singkat LLM:Large Language Model (LLM) adalah model kecerdasan buatan yang didasarkan pada jaringan saraf (neural network) dan dilatih pada sejumlah besar data teks. Tujuannya adalah untuk memproses, memahami, dan menghasilkan bahasa alami manusia agar bisa melakukan berbagai tugas.
Mengapa LLM Jadi Teknologi yang Penting?
Dalam beberapa waktu terakhir, LLM memang jadi pusat perhatian di dunia Artificial Intelligence (AI). Kenapa begitu? Karena kemampuannya yang keren dalam mengolah, memahami, dan menghasilkan teks secara natural, LLM ini jadi pondasi utama di balik berbagai macam kecerdasan buatan generatif (generative AI).
LLM bukan cuma bisa ngobrol atau jawab pertanyaan doang, lho. Kemampuannya mencakup banyak hal, mulai dari:
-
Menghasilkan teks: Bisa nulis artikel, cerita, puisi, skrip, email, bahkan kode program.
-
Meringkas: Mampu merangkum dokumen panjang jadi poin-poin penting yang ringkas.
-
Menerjemahkan: Bisa menerjemahkan bahasa dari satu bahasa ke bahasa lain dengan cukup akurat.
-
Menganalisis teks: Memahami sentimen, mencari informasi spesifik, atau mengklasifikasikan teks.
-
Menjawab pertanyaan: Memberikan informasi berdasarkan data yang telah dipelajarinya.
Berkat kemampuan ini, LLM membuka banyak banget peluang baru. Kita bisa dipakai buat bikin konten yang lebih inovatif, pengalaman percakapan yang lebih interaktif, bahkan sampai membuat berbagai jenis media seperti gambar, video, dan audio.
Gimana Cara Kerja LLM Sampai Bisa Sepintar Robot?

Mungkin banyak dari kita yang penasaran, "Kok bisa sih LLM ngerti dan nulis kayak manusia?" Sebenarnya, di balik kecanggihannya, LLM bekerja dengan prinsip yang bisa dibilang cukup logis, meskipun teknisnya kompleks.
LLM itu dibangun di atas arsitektur jaringan saraf tiruan (neural network) yang canggih. Bayangin jaringan saraf ini kayak otak manusia dengan banyak neuron yang saling terhubung. Nah, neuron-neuron ini tugasnya memproses informasi.
-
Pelatihan (Training) Skala Besar: Tahap paling krusial adalah pelatihan. LLM itu "diberi makan" miliaran bahkan triliunan potongan data teks dan kode dari berbagai sumber. Mulai dari buku, artikel berita, website, percakapan forum, sampai kode dari repositori publik. Selama proses pelatihan inilah, LLM belajar mengenali pola-pola linguistik, hubungan antar kata, struktur kalimat, makna kontekstual, bahkan pengetahuan umum yang tersebar di data tersebut.
Ini mirip kayak anak kecil yang belajar ngomong. Awalnya dia cuma dengerin orang tuanya ngomong, lama-lama dia mulai ngerti kata demi kata, terus nyusun jadi kalimat, dan akhirnya bisa ngomong sendiri. Bedanya, “anak kecil” ini belajarnya dari sumber yang jauh lebih masif.
-
Memahami Konteks: Salah satu kehebatan LLM adalah kemampuannya memahami konteks. Saat kita memberikan sebuah kalimat atau pertanyaan, LLM nggak cuma memproses kata per kata secara terpisah. Dia akan melihat kata-kata di sekitarnya untuk mengerti makna keseluruhan. Ini penting banget, misalnya kata "bisa" punya banyak arti tergantung konteksnya. LLM bisa bedain apakah "bisa" itu artinya kemampuan (dia bisa naik sepeda) atau racun ular (ular berbisa).
-
Memprediksi Kata Berikutnya: Pada dasarnya, saat LLM menghasilkan teks, ia bekerja dengan cara memprediksi kata atau token berikutnya yang paling mungkin muncul berdasarkan konteks yang sudah ada. Misalnya, kalau kita ketik "Langit itu berwarna...", LLM akan memprediksi kata "biru" karena dari jutaan teks yang dia baca, frasa "langit itu berwarna biru" sangatlah umum. Proses prediksi ini terus berlanjut sampai menghasilkan kalimat atau paragraf utuh yang koheren.
Tapi ini bukan cuma sekadar nebak, ya. LLM melakukannya dengan sangat canggih, memperhitungkan probabilitas dari sekian banyak kemungkinan kata yang ada, dan memilih yang paling sesuai dengan konteks dan gaya bahasa yang diinginkan.
Anologi Sederhana: Bayangkan kamu lagi main tebak kata. Kamu dikasih awalan "Saya suka makan...", nah, kamu bisa lanjutin dengan banyak hal kan? "Nasi", "bakso", "apel". LLM melakukan ini ribuan kali lebih kompleks, dengan data miliaran kalimat, dia bisa menebak lanjutan yang paling masuk akal dan natural.
Apa Saja Sih Kemampuan Khas LLM?
LLM itu bukan cuma pintar ngobrol, lho. Kecanggihan mereka bikin mereka bisa melakukan berbagai tugas spesifik yang sangat berguna di berbagai industri.
-
Generasi Teks Kreatif: Bayangkan punya penulis pribadi yang siap kapan saja membuat draf artikel blog, cerita pendek, naskah video, atau bahkan lirik lagu. LLM bisa melakukan itu. Mereka dilatih untuk mengenali berbagai gaya penulisan, jadi bisa menyesuaikan outputnya sesuai permintaan. Misalnya, minta ditulis dengan gaya formal, santai, atau bahkan komedi.
Contohnya, kamu bisa minta LLM untuk:
-
Menulis postingan media sosial tentang produk baru dengan gaya yang menarik.
-
Membuat draf email promosi untuk pelanggan setia.
-
Mengembangkan ide cerita fantasi sederhana.
-
-
Meringkas Informasi Berbobot: Di era kebanjiran informasi ini, kemampuan untuk meringkas jadi kunci. LLM bisa dilatih untuk mencerna dokumen-dokumen panjang, laporan penelitian, atau artikel berita, lalu menyajikannya dalam bentuk ringkasan yang padat informasi. Ini menghemat waktu banget buat para profesional yang harus membaca banyak materi.
Misalnya, skripsi atau tesis yang tebal bisa diringkas poin-poin utamanya, atau berita panjang bisa disajikan dalam beberapa kalimat pokok.
-
Terjemahan dan Adaptasi Bahasa: LLM modern punya kemampuan terjemahan yang semakin presisi, bahkan seringkali lebih baik dari layanan terjemahan standar. Mereka nggak hanya menerjemahkan kata per kata, tapi juga memahami idiom, nuansa budaya, dan konteks kalimat, sehingga hasil terjemahannya terasa lebih natural dan luwes.
Ini sangat membantu buat bisnis internasional, pelajar, atau siapa pun yang perlu berkomunikasi lintas bahasa.
-
Analisis Sentimen dan Umpan Balik: Perusahaan bisa menggunakan LLM untuk memantau percakapan di media sosial atau ulasan pelanggan. LLM bisa menganalisis apakah sentimen publik terhadap produk atau layanan mereka positif, negatif, atau netral. Ini memberikan wawasan berharga untuk perbaikan.
LLM bisa mengidentifikasi keluhan umum, pujian yang sering muncul, atau tren yang sedang dibicarakan.
-
Menghasilkan Kode Program: Ini nih yang bikin LLM keren buat para programmer atau developer. LLM bisa membantu menulis cuplikan kode, menjelaskan kode yang sudah ada, mencari bug, atau bahkan menerjemahkan kode dari satu bahasa pemrograman ke bahasa lain.
Beberapa LLM yang dikhususkan untuk kode bisa menyarankan cara menulis fungsi yang efisien atau bahkan membuat kerangka aplikasi sederhana berdasarkan deskripsi yang kita berikan.
Sejarah LLM: Bagaimana AI Belajar Memahami Bahasa
Meskipun sekarang lagi happening banget, konsep di balik LLM ini sebenarnya udah ada sejak lama. Perkembangan ini nggak muncul tiba-tiba, tapi merupakan hasil dari riset panjang di bidang pemrosesan bahasa alami (Natural Language Processing - NLP) dan machine learning.
Dimulai dari model-model bahasa yang lebih sederhana di masa lalu, peneliti terus menciptakan arsitektur yang lebih canggih dan meningkatkan kemampuan pemrosesan data.
Sejak awal kemunculannya, model bahasa besar (LLM) telah menjadi area yang mengalami kemajuan pesat. Sejarah perkembangannya ditandai dengan peningkatan kapasitas model dan metode pelatihan yang semakin efisien.
Teknologi kunci yang mendorong LLM modern adalah peningkatan kekuatan komputasi dan tersedianya kumpulan data yang masif. Penemuan arsitektur seperti Transformer di tahun 2017 menjadi titik balik penting. Arsitektur ini memungkinkan model untuk memproses urutan kata secara paralel dan sangat efektif dalam menangkap dependensi jarak jauh dalam teks, yang krusial untuk pemahaman bahasa yang mendalam.
Perkembangan ini kemudian melahirkan model-model raksasa seperti seri GPT (Generative Pre-trained Transformer) dari OpenAI, BERT (Bidirectional Encoder Representations from Transformers) dari Google, dan banyak lagi, yang terus mendorong batas kemampuan AI dalam memahami dan menghasilkan bahasa manusia.
LLM vs. AI Generatif: Apa Bedanya?
Seringkali orang nyebut LLM dan AI Generatif itu sama. Padahal, ada perbedaan tipis tapi penting.
-
LLM (Large Language Model): Ini adalah jenis model AI spesifik yang fokus utamanya adalah memahami dan menghasilkan teks dalam bahasa alami. LLM adalah "mesin" utamanya.
-
AI Generatif (Generative AI): Ini adalah kategori teknologi AI yang lebih luas. Tujuannya adalah untuk menciptakan konten baru, bukan hanya menganalisis atau mengklasifikasikan data yang sudah ada. Konten ini bisa berupa teks, gambar, musik, video, bahkan kode.
Jadi, bisa dibilang LLM adalah salah satu jenis teknologi kunci yang memungkinkan AI Generatif bergerak di ranah teks. LLM adalah jantungnya, sementara AI Generatif adalah aplikasinya yang lebih luas.
Misalnya, saat kamu pakai aplikasi yang bisa bikin gambar dari deskripsi teks, atau bikin musik dari ide sederhana, itu adalah contoh AI Generatif. Nah, di balik kemampuan menghasilkan gambar atau musiknya itu, bisa jadi ada pemrosesan bahasa alami yang dilakukan oleh model seperti LLM untuk memahami instruksi teksmu terlebih dahulu.
Cara Kerja LLM Lebih Dalam: Dari Teks Jadi Jawaban
Oke, kita udah bahas dasarnya. Sekarang, mari kita selami sedikit lebih dalam soal gimana sih LLM ini bener-bener bekerja, biar lebih kebayang. Nggak usah takut sama istilah teknisnya, kita bakal coba jabarin pakai analogi yang gampang.
Arsitektur Transformer: Otaknya LLM Modern
Mayoritas LLM modern saat ini dibangun di atas apa yang disebut arsitektur Transformer. Ini adalah terobosan besar di dunia NLP. Sebelum ada Transformer, model seperti Recurrent Neural Network (RNN) dan Long Short-Term Memory (LSTM) sudah ada, tapi punya kekurangan dalam menangani urutan data yang sangat panjang secara efisien.
Nah, Transformer ini ngasih dua kemampuan krusial:
-
Mekanisme Self-Attention: Ini adalah fitur utama Transformer. Mekanisme ini memungkinkan model untuk menimbang seberapa penting setiap kata dalam sebuah kalimat terhadap kata-kata lain dalam kalimat yang sama ketika memprosesnya. Bayangin kamu lagi baca sebuah paragraf. Mata kamu nggak cuma melihat satu kata, tapi juga memperhatikan hubungan kata-kata lain di sekitarnya untuk mengerti makna satu kata tertentu. Self-attention melakukan hal serupa, ia memberikan "skor perhatian" pada setiap kata, sehingga model bisa fokus pada bagian-bagian yang paling relevan dari input teks.
- Contoh Sederhana: Dalam kalimat "Si kancil memakan buah yang ada di pohon itu", mekanisme self-attention akan membantu model memahami bahwa kata "itu" (dalam "pohon itu") sangat berkaitan dengan "pohon", dan tidak berkaitan dengan "kancil" atau "buah" dalam konteks kepemilikan "pohon".
-
Pemrosesan Paralel: Berbeda dengan model sebelumnya yang memproses kata satu per satu secara berurutan, Transformer bisa memproses semua kata dalam sebuah urutan secara bersamaan. Ini bikin latihannya jadi jauh lebih cepat dan efisien, memungkinkan para peneliti untuk melatih model dengan dataset yang lebih besar lagi.
Tokenization dan Embeddings: Bahasa Komputer untuk Kata
LLM nggak ngerti huruf A, B, C, atau kamus bahasa Indonesia secara langsung. Komputer memproses informasi dalam bentuk angka. Jadi, sebelum teks masuk ke dalam model, ada dua langkah penting:
-
Tokenization: Teks dibagi menjadi unit-unit yang lebih kecil, yang disebut token. Token ini bisa berupa kata, bagian kata (sub-word), atau bahkan tanda baca. Misalnya, kalimat "Saya suka LLM." bisa dipecah menjadi token:
["Saya", "suka", "LLM", "."]. -
Embedding: Setelah dipecah jadi token, setiap token akan diubah menjadi sebuah vektor angka (serangkaian nomor). Vektor ini disebut embedding. Nah, uniknya, kata-kata yang punya makna mirip atau sering muncul dalam konteks yang sama akan punya vektor embedding yang posisinya "dekat" di ruang multi-dimensi.
Contoh Analog: Bayangkan kamu punya peta dengan banyak kota. Kota-kota yang dekat secara geografis akan punya koordinat yang berdekatan. Begitu juga dengan embedding, kata "raja" mungkin punya vektor yang dekat dengan "ratu" atau "pangeran" dibandingkan dengan kata "apel".
Jadi, ketika LLM "membaca", ia sebenarnya sedang memanipulasi dan memprediksi urutan dari vektor-vektor angka ini.
Lapisan-Lapisan Kecerdasan: Encoder-Decoder atau Hanya Pihak Tertentu
Arsitektur Transformer standar memiliki dua bagian utama: Encoder dan Decoder.
-
Encoder: Bertugas memahami dan merepresentasikan makna dari input teks. Ia mengambil token embedding dan menghasilkan representasi kontekstual yang kaya.
-
Decoder: Bertugas menghasilkan output teks berdasarkan representasi dari encoder. Ia memprediksi token berikutnya satu per satu.
Namun, banyak LLM modern yang hanya menggunakan bagian Decoder saja (seperti model GPT), atau hanya bagian Encoder saja (seperti model BERT), tergantung pada tugas utamanya.
-
Model yang fokus pada pemahaman dan klasifikasi teks (seperti BERT) cenderung menggunakan arsitektur Encoder.
-
Model yang fokus pada generasi teks (seperti GPT) sangat bergantung pada arsitektur Decoder.
Pelatihan: Belajar dari Kesalahan Miliaran Kali
Proses melatih LLM itu memakan waktu dan sumber daya komputasi yang luar biasa. Model ini terus-menerus disajikan data, membuat prediksi, lalu dibandingkan dengan jawaban yang benar. Perbedaan antara prediksi model dan jawaban yang benar diukur sebagai "loss" atau "kesalahan".
Tujuan pelatihan adalah untuk meminimalkan loss ini. Caranya adalah dengan menyesuaikan jutaan bahkan miliaran parameter (angka-angka internal) dalam jaringan saraf model secara iteratif. Proses penyesuaian ini diatur oleh algoritma optimasi yang canggih, memastikan model "belajar" dari kesalahannya dan semakin akurat dari waktu ke waktu.
Fine-tuning: Mengkhususkan LLM untuk Tugas Tertentu
Dasar LLM sudah sangat kuat dari pelatihan awal (pre-training). Namun, agar lebih efektif untuk tugas-tugas yang sangat spesifik (misalnya, hanya untuk menjawab pertanyaan medis, atau hanya untuk menulis kode Python), LLM biasanya menjalani tahapan fine-tuning.
Pada tahap fine-tuning, model dilatih lagi dengan dataset yang lebih kecil dan lebih spesifik untuk tugas yang diinginkan. Proses ini "menyempurnakan" kemampuan LLM, membuatnya lebih ahli dalam domain tersebut tanpa melupakan pengetahuan umum yang sudah ia pelajari sebelumnya.
Contoh LLM Terkenal dari Berbagai Perusahaan
Saat ngomongin LLM, ada beberapa nama besar yang pasti muncul. Mereka ini adalah hasil dari riset dan pengembangan teknologi AI terdepan di dunia.
-
OpenAI: Perusahaan riset AI ini terkenal dengan seri model GPT mereka (termasuk GPT-3, GPT-3.5, dan GPT-4). Model-model ini sangat populer karena kemampuannya dalam menghasilkan teks yang kreatif, menjawab pertanyaan kompleks, dan bahkan menulis kode. ChatGPT, chatbot yang sangat fenomenal, didukung oleh model GPT ini.
-
Google: Raksasa teknologi ini juga punya sederet LLM canggih. Contohnya adalah BERT (yang dulu sempat sangat dominan dalam tugas pemahaman bahasa seperti Google Search), LaMDA (dikembangkan untuk percakapan), dan yang terbaru PaLM (Pathways Language Model) serta Gemini. Gemini sendiri dirancang sebagai model multimodal yang bisa memahami teks, gambar, audio, dan video secara bersamaan.
-
Meta (Facebook): Meta juga nggak mau ketinggalan. Mereka punya model seperti LLaMA (Large Language Model Meta AI) dan LLaMA 2. Model-model ini sering dirilis dengan lisensi yang lebih terbuka, memungkinkan peneliti dan pengembang lain untuk menggunakannya dan membangun di atasnya.
-
Microsoft: Melalui investasinya di OpenAI, Microsoft menjadi salah satu pemain utama dalam adopsi dan pengembangan LLM. Mereka mengintegrasikan teknologi LLM ke dalam berbagai produk mereka, seperti Bing Chat (yang seringkali didukung oleh model OpenAI).
-
Anthropic: Perusahaan AI yang didirikan oleh mantan peneliti OpenAI ini mengembangkan Claude, sebuah LLM yang dirancang dengan penekanan pada keamanan dan etika AI.
Ini hanyalah beberapa contoh. Masih banyak lagi penelitian dan pengembangan LLM yang dilakukan oleh berbagai perusahaan dan institusi riset di seluruh dunia, masing-masing dengan keunikan dan keunggulannya sendiri.
Potensi dan Manfaat LLM di Kehidupan Sehari-hari dan Bisnis
LLM itu bukan cuma mainan buat para tech enthusiast. Potensinya buat mempermudah dan meningkatkan produktivitas di berbagai bidang itu beneran gede banget.
Untuk Individu: Asisten Pribadi yang Makin Pintar
-
Membantu Belajar: LLM bisa jadi tutor pribadi yang siap menjawab pertanyaan sulit kapan saja, menjelaskan konsep yang rumit dengan bahasa yang mudah dipahami, atau bahkan membuat latihan soal. Misalnya, saat lagi belajar sejarah, kamu bisa tanya detail tentang Perang Diponegoro, dan LLM bisa menjabarkannya.
-
Meningkatkan Produktivitas Menulis: Mau nulis email penting tapi bingung mulai dari mana? Mau bikin caption Instagram yang kece? LLM bisa kasih ide, bantu merangkai kata, atau bahkan mengoreksi tata bahasa.
-
Mencari Informasi Lebih Efisien: Dibandingkan search engine tradisional yang memberimu daftar link, LLM bisa memberikan jawaban langsung dari pertanyaanmu, merangkum informasi dari berbagai sumber, atau bahkan membandingkan opsi.
-
Hiburan dan Kreativitas: Dari membuat cerita pendek, puisi, lirik lagu, sampai skenario film, LLM bisa jadi teman bermain yang nggak ada habisnya buat menuangkan ide kreatif.
Untuk Bisnis: Revolusi Operasional dan Inovasi
-
Layanan Pelanggan Otomatis: Chatbot yang ditenagai LLM bisa menangani pertanyaan pelanggan 24/7, memberikan respons yang cepat dan akurat, serta membebaskan agen manusia untuk menangani kasus yang lebih kompleks.
-
Pembuatan Konten Pemasaran: Membuat deskripsi produk, postingan blog, email newsletter, atau materi iklan jadi lebih cepat dan efisien. LLM bisa membantu menyesuaikan gaya bahasa dengan target audiens.
-
Analisis Data Bisnis: LLM bisa menganalisis dokumen-dokumen internal seperti laporan penjualan, umpan balik pelanggan, atau riset pasar untuk menemukan tren, insight, dan rekomendasi strategis.
-
Pengembangan Produk Baru: Dengan kemampuannya memahami instruksi dan menghasilkan ide, LLM bisa membantu tim riset dan pengembangan dalam brainstorming fitur baru, merancang prototipe, atau menulis dokumentasi teknis.
-
Otomatisasi Tugas Administratif: Mulai dari meringkas notulen rapat, menyusun jadwal, hingga membalas email rutin, LLM bisa mengambil alih tugas-tugas yang memakan waktu.
Kekurangan LLM yang Perlu Kita Tahu
Meskipun sangat powerful, penting untuk diingat bahwa LLM juga punya keterbatasan. Kita perlu sadar akan hal ini supaya penggunaannya lebih bijak dan efektif.
-
Potensi Halusinasi: LLM bisa saja "berhalusinasi" atau menghasilkan informasi yang salah, tidak akurat, atau bahkan mengada-ada, tetapi disajikan dengan sangat meyakinkan. Ini karena model hanya memprediksi kata-kata yang paling mungkin berdasarkan data latihannya, bukan "memahami" kebenaran faktual seperti manusia. Jadi, selalu verifikasi informasi penting yang dihasilkan LLM.
-
Bias dalam Data Latih: Data yang digunakan untuk melatih LLM berasal dari internet, yang mengandung banyak bias yang ada di masyarakat (misalnya bias gender, ras, atau sosial). LLM bisa saja menyerap dan mereproduksi bias-bias ini dalam outputnya.
-
Kurangnya Pemahaman Dunia Fisik: LLM hanya berinteraksi dengan data teks. Mereka tidak punya pengalaman dunia fisik seperti manusia. Jadi, mereka mungkin kesulitan memahami konsep-konsep yang berkaitan dengan ruang, waktu, atau sebab-akibat di dunia nyata jika tidak dijelaskan secara eksplisit dalam teks.
-
Ketergantungan pada Data Terbaru: LLM hanya mengetahui informasi sampai batas data pelatihannya. Jika ada kejadian atau perkembangan baru setelah data tersebut dikumpulkan, LLM mungkin tidak mengetahuinya kecuali ia dilatih ulang dengan data terbaru.
-
Masalah Keamanan dan Privasi: Penggunaan LLM, terutama dalam aplikasi bisnis, perlu perhatian ekstra terhadap keamanan data dan privasi pengguna. Mengirimkan informasi sensitif ke LLM publik bisa berisiko.
-
Penggunaan yang Etis: Ada kekhawatiran tentang potensi penyalahgunaan LLM untuk menyebarkan disinformasi, melakukan penipuan (misalnya phishing yang lebih canggih), atau bahkan menggantikan pekerjaan manusia secara massal.
Masa Depan LLM: Terus Berkembang dan Semakin Terintegrasi
Perkembangan LLM tidak akan berhenti di sini. Para peneliti terus berinovasi untuk mengatasi keterbatasan yang ada dan membuka kemampuan baru.
Beberapa tren masa depan yang mungkin kita lihat:
-
Model yang Semakin Multimodal: LLM akan semakin mahir dalam memproses dan menghubungkan berbagai jenis data, tidak hanya teks, tetapi juga gambar, audio, video, dan bahkan data sensorik lainnya. Ini akan memungkinkan interaksi yang lebih kaya dan pemahaman yang lebih holistik.
-
Peningkatan Keamanan dan Akurasi: Akan ada fokus yang lebih besar pada pengembangan LLM yang lebih andal, mengurangi halusinasi, dan meminimalkan bias. Teknik-teknik seperti reinforcement learning from human feedback (RLHF) akan terus disempurnakan.
-
LLM yang Lebih Spesifik Domain: Kita akan melihat lebih banyak LLM yang dilatih untuk domain-domain khusus (medis, hukum, keuangan, sains) sehingga memberikan keahlian yang lebih mendalam di bidang tersebut.
-
Integrasi Lebih Dalam ke Berbagai Aplikasi: LLM akan semakin terintegrasi ke dalam perangkat lunak yang kita gunakan sehari-hari, dari sistem operasi, aplikasi perkantoran, hingga platform media sosial, menjadikannya bagian tak terpisahkan dari pengalaman digital kita.
-
Perhatian pada Etika dan Regulasi: Seiring dengan semakin kuatnya kemampuan LLM, isu etika, privasi, dan regulasi AI pastinya akan semakin menjadi sorotan dan memerlukan perhatian serius dari berbagai pihak.
LLM adalah salah satu tonggak penting dalam evolusi kecerdasan buatan. Memahaminya bukan hanya soal mengikuti tren teknologi, tapi juga membuka wawasan tentang bagaimana cara kita berinteraksi dengan mesin, menciptakan konten, dan memecahkan masalah di masa depan.
Perbandingan LLM: Mana yang Paling 'Oke' Buat Kita?
Sudah lihat kan, betapa beragamnya LLM yang ada sekarang? Masing-masing punya kelebihan dan kekurangan. Nah, buat kamu yang mungkin lagi nyari LLM buat kebutuhan pribadi atau bahkan buat aplikasi bisnis, perlu banget nih tahu perbandingannya. Ibarat mau beli HP baru, kan ada Samsung, iPhone, Xiaomi, dengan ciri khas masing-masing. Begitu juga LLM.
Secara umum, perbedaan LLM bisa dilihat dari beberapa faktor:
-
Ukuran Model (Jumlah Parameter): Model yang lebih besar (dengan lebih banyak parameter) biasanya punya kemampuan lebih canggih, tapi butuh sumber daya komputasi lebih besar untuk dilatih dan dijalankan.
-
Data Pelatihan: Kualitas dan kuantitas data pelatihan sangat menentukan kapabilitas LLM. LLM yang dilatih dengan data spesifik mungkin lebih unggul di bidang tersebut.
-
Arsitektur: Meskipun banyak yang pakai Transformer, ada variasi dalam detail implementasinya yang bisa memengaruhi kinerja.
-
Tujuan Pengembangan: Ada LLM yang dibuat untuk percakapan umum (chatbot), ada yang fokus pada coding, ada yang untuk analisis teks, dan lain-lain.
-
Aksesibilitas dan Lisensi: Beberapa LLM bersifat open-source dan bisa diunduh serta dimodifikasi, sementara yang lain hanya bisa diakses melalui API berbayar atau produk tertentu.
Mari kita lihat beberapa contoh yang paling sering dibicarakan, dan bagaimana mereka bisa dibandingkan:
1. Seri GPT (OpenAI)

Kelebihan: GPT (terutama GPT-3.5 dan GPT-4) dikenal sangat serbaguna. Kemampuannya dalam memahami instruksi yang kompleks, menghasilkan teks kreatif yang natural, menerjemahkan, meringkas, dan bahkan menulis kode program sangat mengagumkan. GPT-4 bahkan punya kemampuan multimodal (memahami input gambar).
-
Kekurangan: Akses penuh ke model paling canggih (GPT-4) biasanya memerlukan langganan berbayar (ChatGPT Plus) atau melalui API dengan biaya tertentu. Terkadang masih bisa menghasilkan informasi yang sedikit "ngawur" jika instruksinya ambigu atau keluar dari zona nyaman pelatihannya.
-
Cocok Untuk: Penggunaan umum, kreatifitas menulis, pembuatan draf konten, asisten coding, tugas-tugas yang butuh fleksibilitas tinggi.
2. Google PaLM / Gemini

-
Kelebihan: PaLM dan Gemini adalah pesaing kuat GPT. Gemini, khususnya, dirancang sebagai model yang sangat multimodal, artinya ia bisa memproses informasi dari teks, gambar, audio, dan video secara bersamaan. Ini membuka potensi besar untuk pemahaman konteks yang lebih kaya dan aplikasi yang lebih canggih. Google punya keunggulan dalam skala dan infrastruktur AI mereka.
-
Kekurangan: Seperti GPT, akses ke versi paling canggih mungkin terbatas atau berbayar. Fokus awalnya mungkin lebih ke arah integrasi ekosistem Google.
-
Cocok Untuk: Penelitian, aplikasi yang membutuhkan pemahaman lintas modalitas (teks dan gambar, dll.), dan utilitas yang terintegrasi dengan layanan Google.
3. LLaMA / LLaMA 2 (Meta)

-
Kelebihan: Salah satu daya tarik utama LLaMA adalah pendekatannya yang lebih terbuka (open-source) untuk riset. LLaMA 2 dirilis dengan lisensi yang lebih memungkinkan peneliti dan pengembang untuk menjalankan dan memodifikasi model ini di infrastruktur mereka sendiri (dengan batasan tertentu untuk penggunaan komersial skala besar). Ini memberdayakan komunitas AI untuk berinovasi lebih lanjut. Model ini juga menunjukkan performa yang sangat baik di berbagai benchmark.
-
Kekurangan: Menjalankan model sebesar LLaMA secara lokal membutuhkan perangkat keras yang cukup kuat. Meskipun lebih terbuka, masih ada batasan penggunaan tertentu yang perlu diperhatikan.
-
Cocok Untuk: Peneliti AI, developer yang ingin membangun aplikasi kustom dengan kontrol lebih besar, startup yang ingin mengoptimalkan biaya infrastruktur LLM.
4. Claude (Anthropic)

-
Kelebihan: Anthropic sangat menekankan pada pengembangan AI yang aman dan etis melalui pendekatan yang mereka sebut "Constitutional AI". Claude dirancang agar lebih kecil kemungkinannya untuk menghasilkan respons berbahaya, diskriminatif, atau tidak pantas. Model ini seringkali dianggap lebih "hati-hati" dan membantu dalam percakapan yang sensitif.
-
Kekurangan: Mungkin tidak sefleksibel atau se-"kreatif" GPT dalam beberapa tugas yang membutuhkan keberanian mengambil risiko linguistik. Akses mungkin lebih terbatas pada fase awal.
-
Cocok Untuk: Aplikasi yang mengutamakan etika dan keamanan, percakapan yang membutuhkan nada hati-hati dan bertanggung jawab, customer support di industri sensitif.
Bagaimana Memilih LLM yang Tepat?
Pilihannya sangat bergantung pada kebutuhan spesifik kamu:
-
Untuk Eksplorasi dan Penggunaan Pribadi Umum: ChatGPT (versi gratis atau berbayar) adalah pilihan yang sangat baik karena kemudahan akses dan fleksibilitasnya. Gemini juga bisa jadi alternatif menarik.
-
Untuk Pengembang yang Ingin Kontrol Lebih: LLaMA 2 menawarkan opsi open-source yang kuat untuk eksperimen dan pembangunan mandiri.
-
Untuk Aplikasi Bisnis dengan Fokus Keamanan: Claude bisa jadi pilihan yang patut dipertimbangkan karena penekanan etisnya.
-
Untuk Tugas Coding Tingkat Lanjut: GPT-4 atau model-model yang memang dikhususkan untuk coding (seperti Codex dari OpenAI) biasanya jadi pilihan utama.
Penting juga untuk mencoba beberapa model jika memungkinkan. Banyak penyedia LLM menawarkan uji coba gratis atau tingkatan akses yang berbeda, jadi jangan ragu untuk bereksperimen!
Implikasi Sosial dan Etis: Cermin Kemanusiaan di Era AI
Setiap teknologi baru yang powerful selalu datang dengan janji-janji besar sekaligus tantangan yang perlu kita hadapi bersama. LLM, dengan kemampuannya yang luar biasa, tidak terkecuali. Perkembangannya bukan hanya isu teknis, tapi juga punya dampak sosial dan etis yang mendalam.
Mendefinisikan Ulang Pekerjaan dan Keahlian
Salah satu isu yang paling sering dibicarakan adalah bagaimana LLM akan memengaruhi dunia kerja. Bukan rahasia lagi, otomatisasi adalah tren yang terus berjalan. LLM mempercepat tren ini di sektor-sektor yang sebelumnya didominasi oleh pekerjaan kognitif yang melibatkan bahasa.
-
Otomatisasi Tugas Berulang: Tugas-tugas seperti customer service tingkat pertama, penulisan draf laporan standar, entri data, bahkan beberapa aspek penulisan konten marketing, bisa saja diambil alih oleh LLM. Ini bisa meningkatkan efisiensi dan mengurangi biaya bagi perusahaan.
-
Pergeseran Kebutuhan Keahlian: Alih-alih kehilangan pekerjaan, banyak yang berpendapat bahwa LLM akan menciptakan jenis pekerjaan baru dan mengubah jenis keahlian yang dibutuhkan. Akan ada permintaan yang lebih tinggi untuk profesional yang mampu "bekerja bersama" AI. Ini termasuk:
-
AI Prompt Engineer: Orang yang ahli dalam merancang instruksi (prompt) yang efektif untuk LLM agar menghasilkan output yang diinginkan.
-
AI Ethics Specialist: Ahli yang memastikan penggunaan AI dilakukan secara adil, aman, dan bertanggung jawab.
-
AI Integrator: Profesional yang bisa menggabungkan LLM ke dalam sistem dan alur kerja bisnis yang sudah ada.
-
Peneliti dan Pengembang AI: Tetap dibutuhkan untuk terus memajukan teknologi ini.
-
-
Pentingnya Upskilling dan Reskilling: Individu perlu terus belajar dan beradaptasi. Kemampuan untuk menggunakan LLM secara efektif, berpikir kritis terhadap outputnya, dan menggabungkan keahlian manusia dengan kemampuan AI akan menjadi aset yang sangat berharga.
Tantangan Keaslian dan Hak Cipta
Ketika LLM bisa menghasilkan teks yang sangat mirip dengan tulisan manusia, muncul pertanyaan penting tentang keaslian dan hak cipta.
-
Plagiarisme dan Orisinalitas: Bagaimana kita membedakan karya asli manusia dari karya yang dihasilkan LLM? Mahasiswa yang menggunakan LLM untuk mengerjakan tugas, atau penulis yang mengklaim karya LLM sebagai karyanya sendiri, menimbulkan dilema etis dan akademis.
-
Hak Cipta Konten yang Dihasilkan AI: Siapa yang memegang hak cipta atas teks, gambar, atau musik yang dibuat oleh LLM? Apakah pemilik LLM, pengguna yang memberi instruksi, atau AI itu sendiri? Aturan hukum terkait hal ini masih terus berkembang dan belum sepenuhnya jelas di banyak yurisdiksi.
-
Dampaknya pada Kreator Manusia: Seniman, penulis, musisi, dan kreator lainnya khawatir LLM bisa merusak mata pencaharian mereka jika konten yang dihasilkan AI membanjiri pasar dengan biaya produksi yang jauh lebih rendah.
Penyebaran Disinformasi dan Manipulasi
Salah satu kelemahan yang paling mengkhawatirkan dari LLM adalah potensinya untuk digunakan dalam skala besar untuk menyebarkan disinformasi, propaganda, dan konten palsu.
-
Skala Produksi Berita Palsu: LLM memungkinkan siapa saja membuat artikel berita palsu, postingan media sosial yang menyesatkan, atau bahkan skenario penipuan (seperti surat cinta palsu dari orang terkasih, atau email phishing yang sangat personal) dengan sangat cepat dan efisien.
-
Memperkuat Algoritma Polarisasi: Konten yang dihasilkan LLM bisa didesain secara spesifik untuk memicu emosi dan polarisasi dalam masyarakat, memperburuk perpecahan yang sudah ada di platform online.
-
Membanjiri Opini Publik: Jika informasi palsu yang dihasilkan AI ini tersebar luas dan sulit dibedakan dari informasi faktual, hal ini dapat mengikis kepercayaan pada media, sains, dan institusi.
-
Pentingnya Literasi Digital dan Kritis: Masyarakat perlu dibekali dengan kemampuan literasi digital yang kuat dan pola pikir kritis untuk bisa memilah informasi, mengenali tanda-tanda konten palsu, dan tidak mudah percaya pada segala hal yang mereka baca atau lihat secara online.
Pengambilan Keputusan yang Adil dan Tidak Bias
Seperti yang sudah disinggung sebelumnya, LLM bisa mewarisi bias dari data latihannya. Ini punya konsekuensi serius, terutama jika LLM digunakan dalam sistem pengambilan keputusan penting.
-
Bias dalam Rekrutmen: Jika LLM digunakan untuk meninjau resume, ia bisa saja secara tidak sengaja menolak kandidat dari kelompok minoritas jika data latihannya lebih banyak berisi profil kandidat dari kelompok mayoritas yang berhasil.
-
Bias dalam Peradilan atau Pinjaman: LLM yang digunakan dalam analisis risiko di sektor perbankan atau peradilan bisa saja menghasilkan keputusan yang diskriminatif jika bias inheren dalam data historis tidak ditangani dengan baik.
-
Pentingnya Audit Algoritma dan Transparansi: Dibutuhkan mekanisme untuk mengaudit LLM secara berkala untuk mendeteksi dan memperbaiki bias. Transparansi mengenai bagaimana LLM membuat keputusan juga menjadi krusial.
Masalah Privasi Data
Untuk bisa berfungsi dengan baik, banyak LLM memerlukan akses ke data pengguna. Di sinilah isu privasi muncul.
-
Penggunaan Data Pelatihan: Apakah data pribadi pengguna yang tersembunyi di internet digunakan tanpa izin untuk melatih LLM?
-
Keamanan Informasi yang Diinput: Ketika pengguna memasukkan informasi sensitif ke dalam LLM (misalnya, detail pribadi, informasi bisnis rahasia), bagaimana data tersebut disimpan dan dilindungi? Siapa yang bisa mengaksesnya?
-
Peraturan yang Berkembang: Negara-negara di seluruh dunia sedang berupaya keras untuk menciptakan kerangka hukum dan regulasi yang bisa melindungi privasi data di era AI, seperti General Data Protection Regulation (GDPR) di Eropa atau undang-undang serupa yang mulai muncul di berbagai negara.
Perkembangan LLM membawa potensi luar biasa untuk kemajuan peradaban, namun juga menuntut kita untuk secara aktif memikirkan implikasinya. Keterlibatan aktif dari para peneliti, pengembang, pembuat kebijakan, dan masyarakat luas sangatlah penting untuk memastikan teknologi ini berkembang ke arah yang positif dan bermanfaat bagi semua.
LLM di Masa Depan: Lebih dari Sekadar Kata-kata
Kita sudah menjelajahi apa itu LLM, bagaimana cara kerjanya, siapa saja pemain utamanya, dan apa saja dampaknya. Tapi, bagaimana kira-kira gambaran LLM beberapa tahun ke depan? Perjalanan AI selalu penuh kejutan, dan LLM pun diprediksi akan terus berevolusi dengan cara-cara yang mungkin saat ini belum bisa kita bayangkan sepenuhnya.
Salah satu arah perkembangan yang paling menjanjikan adalah kemunculan LLM yang semakin multimodal dan terintegrasi. Seperti yang sudah sedikit dibahas dengan Gemini, masa depan kemungkinan besar bukan lagi sekadar mengolah teks. LLM akan menjadi entitas yang lebih holistik dalam memahami dunia.
Bayangkan sebuah LLM yang tidak hanya bisa membaca deskripsi tentang sebuah ruangan, tetapi juga bisa menganalisis foto ruangan itu, memahami suara percakapan yang terjadi di dalamnya, dan bahkan memprediksi apa yang akan terjadi selanjutnya berdasarkan interaksi antara objek dan penghuninya. Ini membuka pintu untuk aplikasi di bidang:
-
Robotika yang Lebih Cerdas: Robot yang bisa memahami instruksi bahasa manusia secara natural, menafsirkan lingkungan fisik mereka melalui kamera dan sensor, dan berinteraksi dengan dunia secara lebih intuitif.
-
Pengalaman Virtual dan Augmented Reality yang Lebih Imersif: Karakter virtual yang berbicara dan bereaksi secara realistis, interface yang sepenuhnya dikendalikan suara dan gestur, serta lingkungan digital yang dinamis dan responsif.
-
Sistem Rekomendasi yang Lebih Personal: Tidak hanya merekomendasikan film atau musik, tapi juga produk, pengalaman, atau bahkan saran gaya hidup yang benar-benar sesuai dengan preferensi dan konteks pengguna yang kompleks, yang dipahami melalui kombinasi data teks dan non-teks.
-
Bidang Kesehatan yang Lebih Canggih: LLM bisa membantu dokter mendiagnosis penyakit tidak hanya dari laporan medis tertulis, tetapi juga dari hasil pencitraan (seperti CT scan atau MRI), rekaman suara pasien (untuk mendeteksi tanda-tanda penyakit pernapasan atau neurologis), dan bahkan data dari perangkat wearable.
Selain kemajuan multimodal, kita juga akan melihat peningkatan signifikan dalam hal efisiensi dan aksesibilitas. Saat ini, melatih dan menjalankan LLM raksasa membutuhkan sumber daya komputasi yang sangat besar dan mahal. Namun, riset terus dilakukan untuk menciptakan model yang lebih kecil namun tetap powerful, atau untuk mengembangkan metode pelatihan dan inferensi yang jauh lebih hemat energi.
Ini berarti LLM yang sangat canggih mungkin tidak hanya akan tersedia di pusat data besar, tetapi juga bisa berjalan di perangkat yang lebih kecil, bahkan di ponsel pintar kamu, tanpa menguras baterai. Ini akan mendemokratisasi akses ke teknologi AI yang luar biasa ini.
Kemajuan juga akan datang dalam hal "pemahaman mendalam". LLM akan bergerak melampaui sekadar memprediksi kata berikutnya menjadi memiliki pemahaman kausalitas, pemikiran logis yang lebih kuat, dan kemampuan penalaran abstrak yang lebih baik. Ini penting untuk mengatasi salah satu kelemahan terbesar LLM saat ini: kecenderungan untuk "berhalusinasi" atau menghasilkan informasi yang terdengar meyakinkan tetapi sebenarnya salah.
Bayangkan LLM yang tidak hanya bisa meringkas artikel, tetapi juga bisa menganalisis argumen di dalamnya, mendeteksi kelemahan logis, dan bahkan menyarankan penelitian lebih lanjut yang diperlukan untuk mengisi celah pengetahuan.
Tentu saja, seiring dengan kemajuan ini, isu-isu etis dan keamanan yang telah kita bahas akan menjadi semakin relevan dan mendesak. Upaya untuk memastikan LLM bersifat adil, transparan, aman, dan bermanfaat bagi kemanusiaan akan terus menjadi fokus utama. Regulasi yang bijaksana dan kesadaran publik yang tinggi akan menjadi kunci untuk mengarahkan perkembangan LLM ke arah yang benar.
Pada akhirnya, LLM adalah cerminan dari apa yang bisa dicapai oleh kecerdasan buatan ketika digabungkan dengan data dalam skala masif dan pemrosesan cerdas. Ia adalah alat yang luar biasa, dan seperti alat lainnya, potensinya untuk kebaikan atau keburukan sangat bergantung pada bagaimana kita memilih untuk menggunakannya. Per jalanannya ke depan akan membentuk kembali banyak aspek kehidupan kita, mulai dari cara kita bekerja, belajar, berkreasi, hingga cara kita memahami dunia di sekitar kita. Ini adalah era yang menarik untuk menjadi saksi sekaligus partisipan dalam evolusi teknologi yang luar biasa ini.
Referensi
Dicoding. (2026). Mengenal Large Language Model (LLM): Pengertian dan Cara Kerjanya.
IBM. (2026). Apa itu large language models (LLM)?
Wikipedia. (2026). Large language model.
AWS. (2026). Apa itu LLM? - Penjelasan Model Bahasa Besar.
GeeksforGeeks. (2026). Large Language Model (LLM).
AcerID. (2026). Mengenal Large Language Models (LLM), Fungsi, Contoh & Cara Kerjanya.
Cloudcomputing. (2026). Apa itu LLM? Pengertian dan Contoh Penerapannya.
Konsepkoding. (2026). Memahami Large Language Models (LLM): Cara Kerja dan Dampaknya.