Auto
Panduan Lengkap CI/CD Pipeline: Otomatisasi Build, Test, Dan Deploy Software
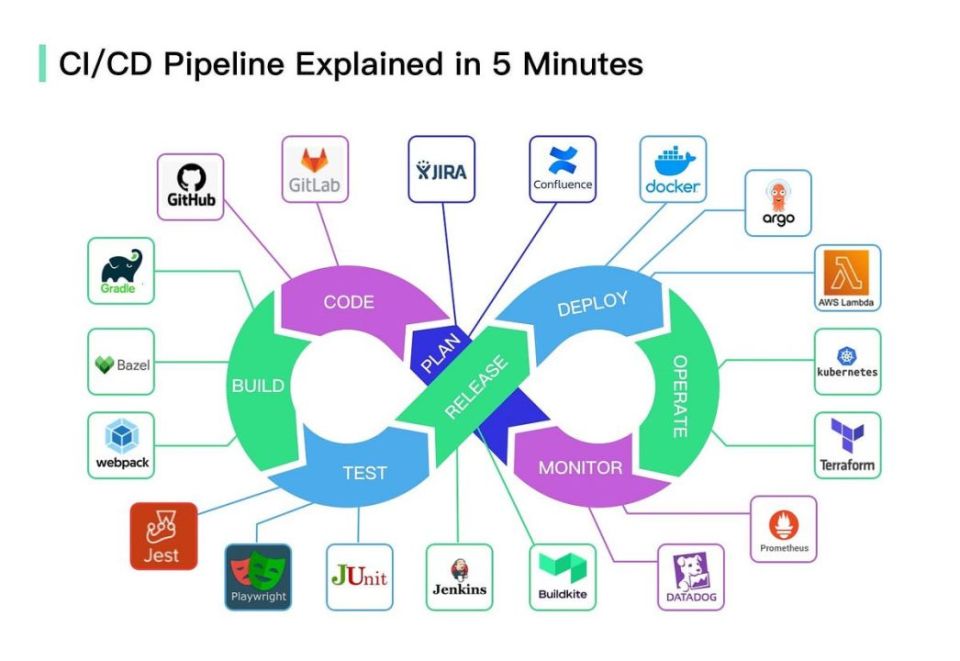
CI/CD adalah fondasi praktik modern pengembangan software yang membantu tim mengotomatisasi proses menggabungkan kode (integration), menguji perubahan, serta mengirimkan rilis ke lingkungan seperti staging dan production secara lebih rutin dan andal. Dengan CI/CD, pekerjaan yang sebelumnya dilakukan manual—mulai dari build, test, sampai deploy—dipindahkan ke jalur otomatis yang konsisten sehingga kualitas rilis lebih terjaga.
Dalam pengembangan perangkat lunak, tim biasanya bekerja di repositori kode sumber pusat dan terus menambahkan perubahan kecil secara berkala. Continuous Integration (CI) menekankan integrasi kode secara teratur dan pengujian otomatis, sementara Continuous Delivery/Deployment (CD) berfokus pada otomasi pengemasan dan pengiriman perubahan setelah lulus rangkaian tes, sehingga rilis bisa lebih cepat dan lebih aman.
Apa itu CI/CD dalam software development?
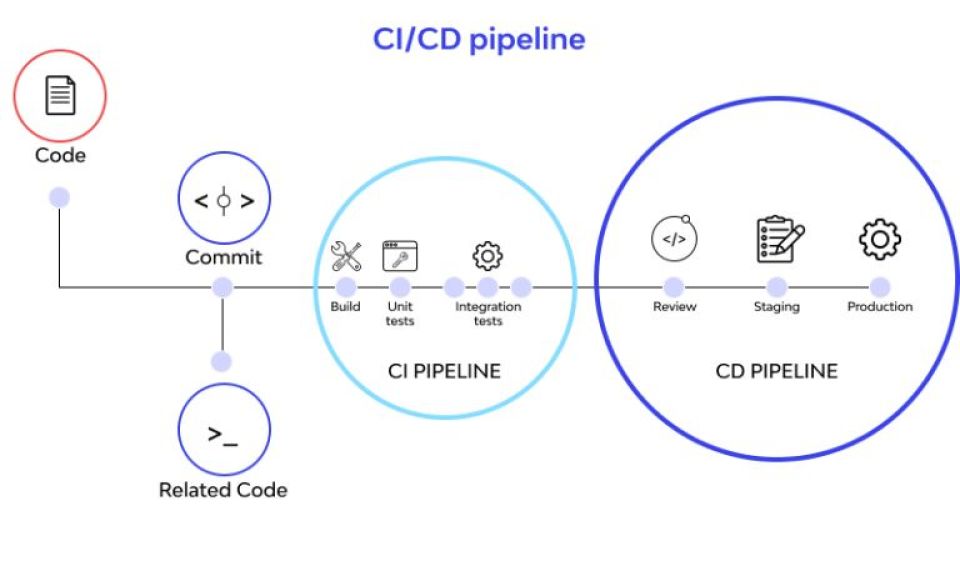
CI/CD adalah serangkaian proses otomatisasi dalam pengembangan perangkat lunak untuk memudahkan developer menggabungkan (merge) kode, menjalankan pengujian, dan mengirimkan (delivery/deployment) aplikasi ke lingkungan target secara konsisten.
Dalam praktiknya, CI/CD menjadi “pipa” (pipeline) yang mengalirkan perubahan dari laptop developer menuju production melalui tahapan-tahapan yang terkontrol. Setiap tahap berisi aktivitas spesifik—misalnya build, unit test, security scan, sampai deploy—dan biasanya disertai pemeriksaan kualitas agar masalah terdeteksi lebih awal sebelum menyebar.
Bedanya CI, Continuous Delivery, dan Continuous Deployment
CI (Continuous Integration): pengembang rutin mengintegrasikan kode baru ke repositori pusat sepanjang siklus pengembangan, lalu pipeline menjalankan build dan tes otomatis.
Continuous Delivery: setelah lulus tes, perubahan siap dirilis kapan pun (biasanya butuh persetujuan manual untuk ke production).
Continuous Deployment: setelah lulus tes, perubahan otomatis dirilis ke production tanpa langkah persetujuan manual (meski tetap bisa ada kontrol seperti canary atau feature flag).
Poin pentingnya: semua Continuous Deployment adalah Continuous Delivery, tetapi tidak semua Continuous Delivery otomatis menjadi Deployment. Pilihannya bergantung pada risiko, budaya kerja, dan kematangan proses tim.
Mengapa CI/CD penting? (Manfaat yang terasa di tim)
CI/CD dibuat untuk membantu tim menghadirkan perubahan software secara rutin dan andal, bukan hanya “lebih cepat”. Kecepatan tanpa kontrol hanya memindahkan masalah lebih cepat ke production.
Manfaat yang umumnya dirasakan:
-
Integrasi lebih aman: perubahan kecil lebih mudah ditinjau diuji dibanding “big bang merge”.
-
Umpan balik cepat: pipeline memberi sinyal cepat ketika ada test gagal, linter error, atau build rusak.
-
Kualitas meningkat: karena tes dan pemeriksaan berjalan konsisten pada setiap perubahan.
-
Rilis lebih sering: proses deploy menjadi kebiasaan yang berulang, bukan momen menegangkan.
-
Mengurangi kerja manual: build/test/deploy tidak lagi mengandalkan langkah “ingat-ingat”.
Konsep inti: CI/CD Pipeline dan tahapannya
Pipeline adalah rangkaian tahapan otomatis yang memproses perubahan kode. Setiap tahap biasanya memiliki “kontrak” yang jelas: jika tahap ini gagal, pipeline berhenti.
Tahapan umum (bisa berbeda per tim):
-
Checkout: mengambil kode dari repositori.
-
Install dependencies: memasang library yang dibutuhkan.
-
Lint/Format: memeriksa standar gaya kode agar konsisten.
-
Build: mengompilasi/menyiapkan artifact.
-
Unit test: memastikan fungsi-fungsi inti bekerja.
-
Integration test: menguji komponen yang saling terhubung (DB, API, dsb).
-
Security/Quality checks: memeriksa kerentanan dan isu teknis lainnya sebelum disebarkan.
-
Package/Artifact: menghasilkan output siap deploy (image container, zip, dll).
-
Deploy ke staging: rilis ke lingkungan uji.
-
Approval / (opsional): persetujuan manual sebelum production.
-
Deploy ke production: rilis final (otomatis atau semi-otomatis).
-
Smoke test & monitoring: cek cepat bahwa aplikasi sehat setelah rilis.
Kenapa tahap-tahap ini penting? Karena setiap tahap memindahkan risiko dari production ke tempat yang lebih aman. Lebih baik pipeline yang “rewel” di awal daripada pengguna yang menemukan bug saat jam sibuk.
Prasyarat (sebelum praktik CI/CD)
Agar tutorial ini mulus, siapkan:
-
Pemahaman dasar Git (commit, branch, pull request).
-
Akses ke platform repositori (contoh: GitHub/GitLab/Bitbucket).
-
Runtime aplikasi sederhana (kita pakai Node.js untuk contoh).
-
Kemampuan menjalankan perintah terminal.
-
(Opsional) Akun cloud atau server untuk target deploy (staging/production).
Jika tim masih baru, mulai dulu dari CI (build + test). CD bisa menyusul setelah tes dan kualitas stabil.
Tutorial: Membangun CI/CD sederhana dari nol (contoh proyek Node.js)

Di bagian ini kita akan membuat pipeline yang:
-
Menjalankan lint dan test setiap ada push/PR (CI).
-
Membangun artifact (build).
-
Melakukan deploy ke “staging” secara otomatis.
-
Menyediakan jalur “production” dengan kontrol (delivery/deployment).
Agar mudah dipahami lintas platform, kita fokus pada struktur dan prinsip. Contoh YAML di bawah menggunakan gaya yang umum dipakai di berbagai tool/CD.
Langkah 1 — Siapkan proyek dan skrip yang akan dipakai pipeline
Buat proyek Node.js sederhana.
mkdir cicd-demo
cd cicd-demo
npm init -y
npm install express
npm install -D eslint jest supertest
Buat file aplikasi src/app.js.
// src/app.js
const express = require("express");
const app = express();
app.get("/health", (req, res) => {
res.json({ status: "ok" });
});
module.exports = app;
Buat src/server.js.
// src/server.js
const app = require("./app");
const port = process.env.PORT || 3000;
app.listen(port, () => {
console.log(`Server running on port ${port}`);
});
Buat test test/health.test.js.
// test/health.test.js
const request = require("supertest");
const app = require("../src/app");
describe("GET /health", () => {
it("returns ok", async () => {
const res = await request(app).get("/health");
expect(res.statusCode).toBe(200);
expect(res.body).toEqual({ status: "ok" });
});
});
Tambahkan script di package.json.
{
"scripts": {
"start": "node src/server.js",
"test": "jest",
"lint": "eslint .",
"build": "node -e \"console.log('build step placeholder')\""
}
}
Kenapa ini penting?
Pipeline CI/CD bekerja paling baik ketika semua langkah penting bisa dijalankan lewat perintah yang jelas (npm test, npm run lint, npm run build). Ini membuat proses konsisten dan bisa diulang di laptop maupun server CI.
Expected output (lokal)
Jalankan:
npm test
Output yang diharapkan (kurang lebih):
PASS test/health.test.js
GET /health
✓ returns ok (xx ms)
Test Suites: 1 passed, total
Tests: 1 passed, 1 total
Langkah 2 — Buat aturan kualitas minimum (linting) agar CI punya “gerbang”
Tambahkan konfigurasi ESLint minimal, misalnya .eslintrc.json.
{
"env": { "node": true, "es2021": true, "jest": true },
"extends": ["eslint:recommended"],
"parserOptions": { "ecmaVersion": "latest" },
"rules": {
"no-unused-vars": "error",
"no-undef": "error"
}
}
Kenapa ini penting?
Linting membuat pipeline mampu menolak perubahan yang secara kualitas dasar sudah bermasalah (misalnya variabel tidak dipakai, typo variabel, dsb). Ini mengurangi noise bug “sepele tapi mahal” di production.
Common error
-
eslint: command not found
Penyebab: eslint belum terpasang sebagai dev dependency.
Solusi:BASHnpm install -D eslint
Langkah 3 — Susun CI: jalankan lint + test pada setiap push/PR
Contoh file pipeline ci.yml (gaya umum):
name: CI
on:
pull_request:
push:
branches: [ "main" ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: "20"
- name: Install deps
run: npm ci
- name: Lint
run: npm run lint
- name: Unit tests
run: npm test
Kenapa ini penting?
CI memastikan setiap perubahan yang masuk ke repositoriwati pemeriksaan yang sama. Ini sejalan dengan praktik CI: developer rutin mengintegrasikan kode ke repositori pusat, lalu pipeline memberi verifikasi otomatis.
Troubleshooting
-
npm cigagal
Umumnya karenapackage-lock.jsontidak sinkron.
Solusi: commitpackage-lock.json, lalu jalankannpm installulang dan commit hasilnya. -
Test flakey (kadang lulus kadang gagal)
Penyebab: test bergantung waktu/urutan/port.
Solusi: isolasi test (gunakan supertest seperti contoh), hindari port tetap, gunakan mocking yang konsisten.
Langkah 4 — Tambahkan build artifact agar siap untuk CD
Jika aplikasi akan dipaketkan (misalnya Docker), buat Dockerfile.
# Dockerfile
FROM node:20-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --omit=dev
COPY src ./src
ENV PORT=3000
EXPOSE 3000
CMD ["node", "src/server.js"]
Tambahkan job build image (contoh):
build:
needs: [test]
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Build image
run: docker build -t cicd-demo:${{ github.sha }} .
Kenapa ini penting?
Artifact membuat hasil build bisa dipindahkan antar environment tanpa “build ulang dengan kondisi berbeda”. Prinsipnya: build sekali, deploy berkali-kali.
Expected output
Saat build sukses, akan ada log layer docker selesai dan image bernama cicd-demo:<sha> terbentuk.
Common error
docker: command not found
Pastikan runner mendukung Docker, atau gunakan runner yang menyediakan Docker.
Langkah 5 — Continuous Delivery: deploy otomatis ke staging
Sekarang buat konsep:
-
staging: tempat uji integrasi sebelum production.
-
production: tempat pengguna nyata.
Contoh “deploy” sederhana untuk staging (misalnya via SSH ke server staging). Buat script scripts/deploy-staging.sh.
#!/usr/bin/env bash
set -euo pipefail
IMAGE_TAG="$1"
echo "Deploying image $IMAGE_TAG to staging..."
# contoh pseudo-steps:
# 1) login registry
# 2) pull image
# 3) restart service
echo "Done."
Pipeline tahap deploy:
deploy_staging:
needs: [build]
runs-on: ubuntu-latest
if: github.ref == 'refs/heads/main'
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Deploy to staging
run: bash scripts/deploy-staging.sh ${{ github.sha }}
Kenapa ini penting?
Continuous Delivery membuat perubahan yang sudah lolos tes bisa selalu tersedia di staging dengan cepat. Tim QA, PM, atau stakeholder bisa mengecek fitur tanpa menunggu “hari rilis”.
Troubleshooting
-
Aplikasi “lulus pipeline” tapi staging rusak
Biasanya karena:-
konfigurasi environment berbeda (ENV VAR, secret, DB)
-
integration test belum cukup mewakili kondisi staging
Solusi: -
samakan konfigurasi lewat
.env.example+ secret manager -
tambah smoke test setelah deploy (
GET /health)
-
Langkah 6 — Tambahkan smoke test setelah deploy (validasi cepat)
Tambahkan step:
- name: Smoke test
run: |
curl -sSf https://staging.example.com/health
Kenapa ini penting?
Smoke test adalah “cekadi” setelah deploy. Walaupun unit test lulus, deploy bisa gagal karena port, routing, sertifikat, atau dependency runtime.
Common error
-
curl: (22) The requested URL returned error: 502
Penyebab: service belum siap atau proxy belum update.
Solusi:-
tambahkan retry/backoff:
BASHfor i in {1..10}; do curl -sSf https://staging.example.com/health && break sleep 3 done
-
Langkah 7 — Continuous Deployment (opsional): produksi otomatis dengan kontrol risiko
Jika tim siap, production bisa otomatis. Namun, kontrol risiko harus jelas.
Praktik aman yang umum:
-
Approval gate sebelum production (manual).
-
Canary release: rilis ke sebagian kecil trafik dulu.
-
Feature flags: aktifkan fitur tanpa deploy ulang.
-
Rollback cepat: otomatis kembali ke versi sebelumnya jika metrik memburuk.
Contoh gate manual (gaya umum):
deploy_production:
needs: [deploy_staging]
runs-on: ubuntu-latest
steps:
- name: Manual approval
run: echo "Approve in the CI system UI"
- name: Deploy to production
run: bash scripts/deploy-production.sh ${{ github.sha }}
Kenapa ini penting?
Continuous Deployment mempercepat rilis, tetapi tanpa pengamanan, kesalahan kecil bisa langsung berdampak ke pengguna. Pipeline seharusnya menyediakan jalur cepat dan aman.
Kesalahan umum saat menerapkan CI/CD (dan cara mengatasinya)
1) Pipeline lambat dan akhirnya di-skip
Gejala: developer menunda push karena “nunggu CI lama”.
Penyebab umum:
-
test terlalu banyak tapi tidak diparalelkan
-
install dependencies tidak di-cache
-
build dilakukan berulang untuk setiap job
baikan:
-
aktifkan caching dependency
-
pecah test menjadi beberapa job paralel
-
gunakan artifact build sekali untuk deploy berikutnya
2) Banyak false positive / flakey tests
Gejala: pipeline merah padahal tidak ada perubahan signifikan.
Penyebab:
-
test bergantung waktu/urutan/IO eksternal
-
data uji tidak di-reset
Perbaikan:
-
isolasi test, gunakan mock/stub untuk dependency eksternal
-
reset database test tiap run
-
hindari test yang bergantung jam sistem
3) “Works on my machine” karena perbedaan environment
Gejala: lokal aman, CI gagal; atau CI lulus, staging gagal.
Perbaikan:
-
samakan versi runtime (Node/Python/JDK)
-
gunakan container untuk menyamakan environment
-
dokumentasikan ENV VAR wajib
4) Secret bocor atau salah kelola
Gejala: token tertulis di repo, atau deploy gagal karena secret tidak ada.
Perbaikan:
-
simpan secret di secret manager CI
-
rotasi token berkala
-
batasi akses secret hanya untuk job deploy
Praktik terbaik (best practices) CI/CD yang realistis
-
Mulai dari CI: lint + unit test + build.
-
Rilis kecil tapi sering: perubahan kecil lebih mudah dipantau.
-
Buat quality gate jelas: definisikan syarat “boleh merge”.
-
Automasi pemeriksaan kualitas: termasukji otomatis dan pemeriksaan kelemahan teknis sebelum disebarkan.
-
Observability: log, metrics, tracing untuk mendeteksi dampak rilis.
-
Dokumentasikan pipeline: bukan hanya YAML, tapi “kenapa begini”.
Product Review: CI/CD sebagai “produk proses” untuk tim software
Bagian ini membahas CI/CD seperti menilai sebuah produk: fitur, kelebihan, kekurangan, dan kecocokan.
Overview: apa yang “dibeli” tim ketika mengadopsi CI/CD?
CI/CD “menjual”:
-
Otomatisasi proses integrasi dan deployment
-
Konsistensi langkah build/test/release
-
Kecepatan rilis dengan kontrol kualitas
-
Keandalan karena proses dapat diulang dan diaudit
Di banyak tim, CI/CD bukan sekadar tool, melainkan perubahan cara kerja: dari rilis episodik ke rilis berkelanjutan.
Key features yang paling bernilai
-
Pipeline bertahap: build → test → package → deploy.
-
Automated testing: memeriksa kualitas dan masalah teknis sebelum disebarkan.
-
Gates & approvals: kontrol sebelum production.
-
Artifact management: build sekali, deploy berkali-kali.
-
Environment support: dev/staging/production.
-
Integrasi repo: berjalan pada push/PR, sehingga feedback cepat.
Real-world use cases (contoh penerapan)
-
SaaS / web app: rilis fitur kecil setiap hari.
-
Mobile backend: deploy cepat dengan kontrol rollback.
-
Microservices: setiap service punya pipeline sendiri, tapi standar kualitas sama.
-
Tim data/ML (sebagian): untuk training & deploy model (lebih kompleks tapi prinsip mirip).
Pros (kelebihan)
-
Mengurangi human error dalam deploy.
-
Mempercepat feedback untuk kualitas kode.
-
Mendukung rilis rutin dan andal, cocok untuk kebutuhan bisnis yang dinamis.
-
Meningkatkan kolaborasi karena integrasi dilakukan terus-menerus.
Cons (kekurangan)
-
Biaya awal: setup pipeline, test, dan environment butuh waktu.
-
Butuh disiplin: tanpa kebiasaan commit kecil & test yang baik, CI/CD jadi “pabrik gagal”.
-
Kompleksitas bertambah: terutama untuk multi-environment, secret, dan infra.
-
False sense of security: pipeline hijau bukan jaminan bebas bug jika cakupan tes lemah.
Cocok untuk siapa?
-
Tim yang ingin rilis lebih sering dengan standar kualitas yang konsisten.
-
Produk yang butuh kecepatan iterasi (startup maupun enterprise).
-
Tim dengan budaya kolaboratif dan siap menulis test.
Siapa yang sebaiknya menunda dulu?
-
Tim yang belum punya kontrol versi yang rapi.
-
Proyek yang jarang berubah dan tidak butuh rilis rutin.
-
Sistem legacy yang belum bisa ditest otomatis sama sekali (mulai dari CI minimal dulu).
Verdict (penilaian seimbang)
CI/CD adalah investasi proses yang biasanya “balik modal” ketika tim mulai sering rilis dan bug production menjadi mahal. Nilai tertingginya muncul saat CI/CD dipadukan dengan testing yang memadai dan rilis yang bijak (delivery vs deployment), bukan sekadar “otomatis deploy”.
Case Study: Migrasi rilis manual ke CI/CD di tim produk (naratif + metrik)
Background
Sebuah tim mengelola aplikasi web dengan rilis mingguan. Proses rilis manual memerlukan koordinasi lintas anggota tim dan sering memakan waktu lama.
Tim ingin membuat perubahan bisa dikirim lebih rutin, tanpa menurunkan kualitas.
Challenge/Problem
Masalah utama yang muncul:
-
Merge besar di akhir minggu membuat konflik dan bug sulit dilacak.
-
Deploy manual rawan lupa langkah tertentu.
-
Saat rilis gagal, rollback lambat karena tidak ada artifact yang konsisten.
-
Uji dilakukan tidak konsisten; kadang hanya “klik-klik manual”.
Approach
Tim memutuskan bertahap:
-
Terapkan CI terlebih dulu: lint + unit test + build untuk setiap PR.
-
Bangun pipeline staging otomatis (Continuous Delivery).
-
Tambahkan smoke test dan monitoring pasca deploy.
-
Baru mempertimbangkan production dengan approval gate.
Implementation
Langkah implementasi yang dilakukan:
-
Menstandarkan perintah:
-
npm run lint -
npm test -
npm run build
-
-
Menambahkan test untuk endpoint kritikal (
/health, login basic flow). -
Menyiapkan staging yang mirip production (ENV VAR, reverse proxy).
-
Membuat pipeline bertahap:
-
PR → CI wajib lulus sebelum merge
-
merge ke main → deploy otomatis ke staging
-
deploy production → butuh persetujuan + smoke test
-
Kenapa pendekatan ini efektif?
ena sesuai prinsip CI: integrasi sering dengan verifikasi otomatis. CD kemudian memastikan perubahan yang lulus tes dapat dikirim secara konsisten, dan pipeline menyediakan pemeriksaan kualitas sebelum menyebar lebih luas.
Results (dengan metrik yang masuk akal)
Setelah 6 minggu:
-
Frekuensi rilis naik dari 1x/minggu menjadi 3–5x/minggu (rilis kecil).
-
Waktu rata-rata dari merge ke staging turun dari ~2 jam menjadi ~10–15 menit (pipeline otomatis).
-
Insiden deploy karena “langkah manual terlewat” turun drastis (mendekati nol).
-
Bug production berkurang karena issue tertangkap di CI/staging lebih awal (indikator: penurunan hotfix).
Catatan: angka bisa bervariasi antar tim, tetapi pola umumnya sama—otomatisasi dan konsistensi mengurangi kerja manual dan mempercepat feedback.
Key Learnings
-
CI dulu, CD belakangan: tanpa CI yang kuat, CD hanya mempercepat pengiriman bug.
-
Test kecil yang stabil lebih bernilai daripada test banyak tapi flakey.
-
Staging yang mirip production mengurangi kejutan.
-
Gate production tidak harus dihapus; yang penting alur rilis tetap cepat dan terkendali.
Comparison Guide: Memilih pendekatan dan tool CI/CD (side-by-side)
Di bawah ini perbandingan opsi CI/CD berdasarkan skenario umum. Fokusnya bukan “mana paling keren”, tetapi “mana paling cocok”.
Tabel perbandingan opsi CI/CD (ringkas)
Opsi | Kekuatan utama | Kelemahan utama | Cocok untuk | Catatanasi |
|---|---|---|---|---|
CI/CD terintegrasi repo (mis. GitHub Actions/GitLab CI) | Setup dekat dengan code & PR, mudah trigger | Bisa kompleks saat scaling besar | Tim kecil-menengah, product iterasi cepat | Simpan pipeline sebagai YAML di repo |
CI/CD berbasis server (mis. Jenkins) | Sangat fleksibel, bisa custom ekstrem | Perlu maintenance server & plugin | Enterprise, kebutuhan integrasi khusus | Butuh disiplin keamanan & upgrade |
CI/CD cloud-native (mis. AWS CodePipeline) | Integrasi kuat dengan layanan cloud | Lebih “terikat” ekosistem vendor | Produk yang sudah di cloud vendor | Cocok untuk deploy ke layanan vendor |
CD GitOps (mis. Argo CD/Flux) | Deklaratif, audit rapi, cocok Kubernetes | Kurva belajar, butuh cluster matang | Tim platform, microservices di K8s | Pisahkan repo app vs repo config |
Kriteria memilih (breakdown)
1) Kecepatan setup
-
Paling cepat: CI/CD yang sudah terintegrasi dengan repo.
-
Paling berat: server CI/CD self-hosted.
Kenapa penting?
Jika tim baru mulai, kemenangan cepat membuat adopsi berlanjut. Terlalu kompleks di awal sering membuat pipeline ditinggalkan.
2) Kontrol & fleksibilitas
-
Paling fleksibel: Jenkins/self-hosted.
-
Paling “opinionated”: cloud-native/GitOps (tetap fleksibel, tapi ada polau).
Kenapa penting?
Beberapa organisasi punya kebutuhan compliance, jaringan internal, atau integrasi legacy yang butuh fleksibilitas tinggi.
3) Kebutuhan infra & maintenance
-
Repo-integrated: maintenance rendah.
-
Self-hosted: maintenance tinggi.
Kenapa penting?
CI/CD itu “produk internal”. Kalau tim harus sibuk merawatnya, fokus ke produk utama bisa terganggu.
4) Dukungan environment dan rilis aman
Semua opsi bisa, tetapi tingkat kemudahan berbeda. Pertimbangkan:
-
dukungan secret management
-
approval gate
-
strategi canary/blue-green
-
rollback otomatis
Best-for scenarios (rekomendasi per use case)
-
Startup / tim kecil: pilih CI/CD terintegrasi repo untuk CI + staging CD. Tambahkan gate untuk production saat perlu.
-
Enterprise dengan integrasi kompleks: pertimbangkan self-hosted (atau managed) yang fleksibel, tetapi tetapkan standar pipeline agar tidak “spaghetti”.
-
Produk heavy di satu cloud vendor: CI/CD cloud-native biasanya paling mulus untuk izin, artifact, dan deploy.
-
Kubernetes microservices skala besar: GitOps CD memberi audit trail kuat dan konsistensi deployment.
Rekomendasi akhir berdasarkan kebutuhan
-
Jika tujuan utama: cepat mulai + konsisten → repo-integrated CI/CD.
-
Jika tujuan utama: kontrol penuh → self-hosted (dengan biaya maintenance).
-
Jika tujuan utama: integrasi cloud mendalam → cloud-native.
-
Jika tujuan utama: deploymentatif & audit kuat di K8s → GitOps CD.
Checklist implementasi CI/CD yang bisa langsung dipakai tim
Checklist CI (wajib)
-
Semua PR menjalankan lint
-
Semua PR menjalankan unit test
-
Build menghasilkan artifact yang konsisten
-
Aturan merge: “CI harus hijau”
Checklist CD (staging)
-
Deploy otomatis dari main ke staging
-
Smoke test setelah deploy
-
Konfigurasi staging mirip production
-
Log & monitoring minimal aktif
Checklist production (bertahap)
-
Approval gate (minimal di awal)
-
Rollback plan (jelas dan cepat)
-
Strategi rilis aman (canary/blue-green/feature flag)
-
Observability untuk mendeteksi regresi cepat
Troubleshooting lanjutan: saat pipeline sudah jalan tapi hasilnya belum memuaskan
Masalah: “Kami sudah CI/CD, tapi bug production tetap banyak”
Penyebab paling sering:
-
Tes tidak mencakup skenario kritikal.
-
Tidak ada integration test untuk komponen yang sering berubah.
-
Tidak ada validasi pasca-deploy (smoke test minim).
Solusi praktis:
-
Tambah test untuk jalur bisnis utama (login, checkout, pembayaran, dsb).
-
Tambahkan contract test antar service jika microservices.
-
Wajibkan smoke test endpoint kritikal sebelum menandai deploy sukses.
Masalah: “Deploy sering gagal karena perbedaan konfigurasi”
Solusi:
-
Dokumentasikan konfigurasi melalui:
-
.env.example -
validasi ENV VAR saat startup (fail fast)
-
-
Gunakan secret manager CI, bukan file lokal.
-
Buat “config checklist” per environment.
Masalah: “Pipeline aman, tapi rilis lambat karena approval”
Solusi:
-
Gunakan approval untuk production.
-
Automasi rilis ke staging agar feedback cepat.
-
Terapkan feature flags agar rilis code tidak selalu berarti rilis fitur.
Masalah: “Tim takut Continuous Deployment”
Pendekatan bertahap:
-
Mulai dari Continuous Delivery (siap rilis kapan pun).
-
Tambah observability dan rollback.
-
Uji strategi canary di scope kecil dulu.
Glosarium singkat istilah CI/CD (biar tidak rancu)
-
Pipeline: rangkaian tahapan otomatis dari build sampai deploy.
-
Artifact: hasil build yang siap dipindahkan/deploy.
-
Staging: environment mirip production untuk uji sebelum rilis.
-
Gate: syarat/approval agar pipeline lanjut.
-
Smoke test: tes cepat setelah deploy untuk memastikan layanan hidup.
-
Rollback: kembali ke versi sebelumnya jika terjadi masalah.uk memastikan layanan hidup.
-
Rollback: kembali ke versi sebelumnya jika terjadi masalah.
Praktik lanjutan: Quality gate yang “bernilai”, bukan sekadar formalitas
Pada tahap awal, banyak tim merasa sudah “ber-CI/CD” karena pipeline bisa jalan. Namun, nilai sebenarnya baru terasa ketika pipeline menjadi quality gate yang benar-benar menjaga mutu, bukan sekadar rangkaian langkah yang selalu di-bypass.
Quality gate yang sehat biasanya punya tiga ciri:
-
Syaratnya jelas dan terukur
Contoh: lint wajib lulus, unit test wajib lulus, dan minimal ada smoke test setelah deploy. -
Waktunya masuk akal
Jika gate terlalu lama, developer akan terdorong mencari jalan pintas. -
Tindak lanjutnya cepat
Pipeline gagal harus menghasilkan sinyal yang mudah ditindaklanjuti (log jelas, error spesifik, dan langkah perbaikan terarah).
Gate 1 — Branch protection: jadikan CI “tiket masuk” ke main
Dalam gaya repo-integrated (seperti GitHub Actions), penguatan paling sederhana adalah: PR tidak boleh di-merge jika CI merah. Ini terdengar sepele, dampaknya besar: main tetap stabil, dan CD ke staging tidak menjadi “pemindah masalah”.
Checklist kebijakan yang biasanya efektif:
-
PR harus melalui review (minimal 1 reviewer).
-
CI (lint + unit test) wajib hijau.
-
Tidak boleh langsung push ke main (wajib lewat PR).
-
Squash merge atau merge commit: pilih salah satu dan konsisten.
Kalau tim masih baru, jangan langsung menambahkan 10 gate sekaligus. Mulai dari yang paling “mengembalikan modal”: lint + unit test.
Gate 2 — Coverage dan “definisi lulus” yang realistis
Banyak tim terpancing memasang target coverage tinggi sejak awal, lalu frustrasi karena pipeline jadi beban. Pendekatan yang lebih baik:
-
Fokus dulu pada test untuk jalur kritikal (contoh: autentikasi, pembayaran, endpoint kesehatan, proses utama bisnis).
-
Tambahkan coverage sebagai metrik pemantauan, bukan pengunci, pada fase awal.
-
Setelah test suite stabil dan tim sudah terbiasa, barulah coverage dijadikan gate bertahap.
Jika ingin menambahkan coverage di proyek Node.js contoh, Anda bisa menyalakan laporan coverage Jest:
{
"scripts": {
"test": "jest --coverage"
}
}
Lalu hasilnya bisa disimpan sebagai artifact atau dibaca pada log. Ini memberi visibilitas tanpa langsung “menghukum” tim dengan aturan yang terlalu keras.
Security checks: kapan perlu, dan bagaimana agar tidak memperlambat tim
Di artikel CI/CD, security sering disebut, tetapi penerapannya salah kaprah: scan di semua tempat, semua waktu, lalu pipeline jadi lambat dan banyak false positive. Strategi yang lebih rapi adalah memecahnya berdasarkan tujuan:
1) Dependency vulnerability scan (paling cepat memberi manfaat)
Untuk proyek Node.js, banyak masalah keamanan datang dari dependency. Langkah minimal:
-
Jalankan audit pada schedule (harian/mingguan), dan juga pada PR untuk perubahan dependency yang besar.
-
Prioritaskan kerentanan dengan severity yang jelas (misalnya high/critical).
Kuncinya: jangan membuat developer tenggelam dalam noise. Jika scanner sering memberi temuan tidak relevan, tim akan kebal terhadap peringatan.
2) Secret scanning (mencegah insiden paling memalukan)
Kebocoran token ke repo sering terjadi karena kesalahan kecil. Praktik yang aman:
-
Jangan menyimpan secret di file yang di-commit.
-
Simpan secret di secret manager CI.
-
Pastikan job deploy saja yang boleh mengakses secret deploy.
Dalam “product review” kacamata proses, secret management adalah fitur yang nilainya sangat tinggi: risiko besar, biaya pencegahan relatif kecil.
Artifact management yang benar: “build sekali, pakai berkali-kali”
Di bagian sebelumnya, kita sudah menyinggung prinsip build sekali, deploy berkali-kali. Ini bukan slogan; ini mengurangi kelas masalah yang sering terjadi:
-
“CI lulus tapi staging” karena build dilakukan ulang dengan kondisi berbeda.
-
Rollback lambat karena tidak ada artifact yang terdokumentasi.
-
Produksi tidak bisa diaudit karena tidak jelas build mana yang digunakan.
Praktik yang disarankan
-
Tetapkan penamaan artifact yang jelas: pakai commit SHA atau versi semantik.
-
Simpan artifact pada registry (contoh: container registry) atau storage artifact CI.
-
Deploy staging dan production memakai artifact yang sama, hanya beda konfigurasi environment.
Jika menggunakan Docker image, id yang stabil (SHA) sangat membantu: staging dan production menunjuk image yang sama, sehingga perbedaan hasil lebih mudah dilacak ke konfigurasi, bukan build.
Strategi deployment: blue-green vs canary vs rolling (perbandingan praktis)
Ketika tim mulai serius dengan CD, pertanyaan berikutnya bukan lagi “bisa deploy”, melainkan bagaimana deploy yang aman. Di sinilah gaya comparison-guide benar-benar berguna.
1) Rolling deployment
Cara kerja: instance diperbarui bertahap. Sebagian lama, sebagian baru, lalu bergeser.
-
Kelebihan: sederhana, cocok default di banyak platform.
-
Kekurangan: jika ada perubahan skema DB yang tidak kompatibel, bisa terjadi masalah saat versi lama dan baru berjalan bersamaan.
-
Cocok untuk: layanan stateless dengan kompatibilitas versi yang dijaga.
2) Blue-green deployment
Cara kerja: ada dua lingkungan identik (blue dan green). Versi baru dipasang di “green”, lalu traffic dialihkan sekaligus.
-
Kelebihan: rollback cepat (tinggal switch).
-
Kekurangan: butuh resource dobel, dan pengelolaan state perlu disiplin.
-
Cocok untuk: aplikasi yang butuh kepastian cutover, serta rollback yang sangat cepat.
3) Canary release
Cara kerja: rilis versi baru ke sebagian kecil traffic dulu, pantau metrik, lalu tingkatkan bertahap.
-
Kelebihan: risiko terkendali, deteksi regresi lebih cepat sebelum semua pengguna terdampak.
-
Kekurangan: butuh observability matang dan strategi segmentasi traffic.
-
Cocok untuk: produk dengan traffic cukup, dan tim yang siap memantau metrik.
Kalau tim masih tahap awal, rolling + gate + rollback sederhana sering sudah cukup. Canary biasanya masuk setelah monitoring, alerting, dan metrik bisnis sudah dapat dipercaya.
Feature flags: pemisah antara “rilis kode” dan “rilis fitur”
Salah satu penyebab rilis menjadi momen tegang adalah ketika deploy selalu berarti fitur langsung aktif untuk semua orang. Feature flags memberi jalan tengah:
-
Kode dapat masuk production lebih sering (pipeline tetap cepat).
-
Aktivasi fitur dapat dikontrol (per pengguna, per segmen, atau per waktu).
-
Rollback fitur dapat dilakukan tanpa redeploy (cukup matikan flag).
Dalam kerangka kerja CI/CD, feature flags juga membantu transisi dari Continuous Delivery ke Continuous Deployment. Anda bisa tetap mengotomatiskan deploy, tetapi kontrol risiko ada pada flag.
Praktik yang baik:
-
Setiap flag harus punya pemilik (owner).
-
Ada tanggal evaluasi/penutupan (flag yang dibiarkan selamanya akan menjadi beban teknis).
-
bukan pengganti test; ia alat manajemen risiko, bukan alasan mengabaikan kualitas.
Observability sebagai bagian pipeline: bukan pekerjaan “setelah produksi”
Banyak tim menganggap monitoring adalah urusan operasional. Padahal, untuk rilis yang rutin, observability adalah “sensor” yang membuat CD layak dilakukan.
Minimal observability yang biasanya diperlukan:
-
Log terstruktur (setidaknya level info/error).
-
Metrics: latency, error rate, throughput.
-
Alert: indikator sederhana ketika rilis berdampak buruk (misalnya error rate melonjak).
Praktik kecil yang sering memberikan dampak besar
-
Tambahkan step “post-deploy check” selain smoke test.
-
Tetapkan SLO sederhana: misalnya error rate < X% selama Y menit setelah deploy.
-
Jika gagal, pipeline bisa menandai rilis sebagai bermasalah dan memicu rollback atau intervensi manual.
Perhatikan: ini tidak harus langsung “otomatis rollback” dari hari pertama. Banyak tim memulai dari deteksi dan notifikasi, lalu naik kelas ke otomatisasi ketika sudah percaya pada metriknya.
Case Study mini: dari staging stabil ke produksi lebih berani (fase 2)
Pada studi kasus sebelumnya, tim sudah berhasil menaikkan frekuensi rilis dan menurunkan waktu deploy ke staging. Fase berikutnya biasanya seperti ini:
Situasi baru
-
Staging sudah otomatis dan cukup stabil.
-
Hotfix produksi menurun, tetapi masih ada beberapa insiden regresi pada jam sibuk.
-
Approval gate produksi masih membuat rilis terasa lambat saat ada perubahan.
Intervensi yang dilakukan (bertahap)
-
Perkuat smoke test: bukan hanya
/health, tetapi juga satu skenario “jalur utama” (misalnya login dummy atau request API yang paling sering dipakai). -
Tambahkan monitoring pasca deploy: pantau error rate dan latency selama 10–15 menit setelah rilis.
-
Gunakan canary sederhana: rilis ke sebagian kecil traffic terlebih dahulu (misalnya 5%), lalu naikkan jika metrik stabil.
-
Feature flags untuk perubahan berisiko: deploy boleh otomatis, aktivasi fitur dilakukan bertahap.
Dampak yang biasanya terlihat
-
Tim lebih berani meningkatkan otomatisasi, karena ada sensor (observability) dan rem (rollback/flag).
-
Approval gate tidak harus hilang, tetapi lebih jarang menjadi penghambat, karena rilis yang berisiko tinggi sudah “dipisahkan” lewat canary dan flag.
Pola ini konsisten: produksi menjadi lebih aman bukan karena “lebih banyak aturan”, melainkan karena kontrol risiko berada di tempat yang tepat.
Checklist tambahan (lanjutan) untuk tim yang sudah melewati tahap dasar
Berikut checklist yang dapat dipakai setelah CI + staging CD berjalan stabil:
Checklist kualitas lanjutan (CI)
-
Ada aturan branch protection PR review
-
Test suite stabil (flaky test ditangani)
-
Dependency scan berjalan rutin dan temuan ditriase
-
Secret dikelola via CI secret manager, bukan file repo
-
Artifact disimpan dan dapat dilacak (versi/SHA jelas)
Checklist rilis aman (CD production)
-
Ada strategi deployment (rolling/blue-green/canary)
-
Ada langkah verifikasi pasca deploy (smoke + metrik)
-
Ada prosedur rollback yang cepat dan terlatih
-
Ada feature flags untuk perubahan yang berisiko
-
Akses deploy dibatasi dan teraudit
Bagian berikutnya biasanya masuk ke contoh implementasi yang lebih “nyata” untuk production workflow (misalnya pemisahan workflow CI vs CD, environment protection, dan pola branch/release).ment protection, dan pola branch/release).
Referensi
Blog. (2026). Mengenal CI/CD - Continuous Integration dan Continuous Deployment.
Aws. (2026). Apa yang dimaksud CI/CD? - CI/CD Dijelaskan - AWS.
Dibimbing. (2026). Mengenal CI/CD: Cara Kerja, Manfaat, dan Contohnya.
Ibm. (2026). Apa itu CI/CD? | IBM.
Codepolitan. (2026). Apa Itu CI/CD? IT Developer Harus Tau! - CODEPOLITAN.
Rumahweb. (2026). Panduan CI/CD untuk Pemula: Dari Development ke Production.
Aws. (2026). Apa itu Jalur CI/CD? - Penjelasan Jalur CI/CD - AWS.
Id. (2026). Mengenal CI/CD: Kunci untuk Proses Pengembangan yang Cepat dan Efisien.