Programming
Moonshot AI Merilis Kimi K2.7-Code, Model AI Khusus Coding

Moonshot AI hari ini merilis Kimi K2.7-Code sebagai model coding agentic yang dirancang untuk pekerjaan rekayasa perangkat lunak nyata: membaca basis kode besar, menjalankan alur multi-langkah, memakai tool, memperbaiki bug, dan menghasilkan perubahan kode yang konsisten. Yang menarik bukan hanya klaim “model coding baru”, tetapi posisinya sebagai penerus Kimi K2.6 dengan fokus lebih tajam pada produktivitas coding agent, konteks panjang 256K, mandatory thinking mode, arsitektur 1T-parameter MoE, serta akses API yang kompatibel dengan ekosistem OpenAI dan Anthropic.
Artikel ini membandingkan Kimi K2.7-Code dengan kebutuhan nyata tim engineering: apakah ia cocok untuk menggantikan model coding tertutup, apakah open-weight memberi nilai praktis, dan bagaimana dampaknya terhadap biaya, kecepatan, serta kualitas kerja agent. Pembahasannya dibuat sebagai review produk, studi kasus, problem-solution guide, dan tutorial implementasi agar pembaca bisa menilai dari sisi strategi maupun teknis.
Apa Itu Kimi K2.7-Code?

Kimi K2.7-Code adalah model coding agentic open-weight dari Moonshot AI yang dioptimalkan untuk tugas software engineering jangka panjang, penggunaan tool, reasoning terstruktur, dan pemrosesan konteks besar hingga sekitar 256K token.
Model ini diposisikan sebagai penerus coding-focused dari Kimi K2.6. Moonshot AI menekankan peningkatan pada performa coding, agent behavior, dan tugas long-horizon coding yang lebih dekat dengan pekerjaan developer sehari-hari.
Secara ringkas, Kimi K2.7-Code mencoba menjawab satu pertanyaan penting: bisakah model open-weight menangani pekerjaan coding agent serius tanpa biaya dan keterbatasan model proprietary?
Ringkasan Spesifikasi Utama
Aspek | Kimi K2.7-Code |
|---|---|
Pengembang | Moonshot AI |
Fokus utama | Coding agent, software engineering, tool use |
Model ID | kimi-k2.7-code |
Arsitektur | 1T-parameter MoE |
Konteks | 256K, disebut juga sekitar 262.1K pada beberapa platform |
Mode reasoning | Mandatory / forced thinking mode |
Efisiensi | Sekitar 30% lebih sedikit reasoning token dibanding K2.6 |
Akses | API Moonshot/Kimi, OpenAI-compatible, Anthropic-compatible |
Deployment | Direkomendasikan dengan vLLM dan SGLang |
Quantization | Native INT4 quantization |
Platform tambahan | Tersedia di Cloudflare Workers AI |
Lisensi | Open-weight, disebut dengan Modified MIT pada beberapa publikasi |
Mengapa Rilis Ini Penting untuk Developer?
Banyak model AI coding terlihat mengesankan dalam demo singkat, tetapi gagal ketika dihadapkan pada basis kode besar, dependency yang rumit, instruksi panjang, atau perubahan lintas-file. Kimi K2.7-Code hadir dengan positioning yang lebih spesifik: bukan sekadar chatbot coding, melainkan agent coding untuk workflow software engineering.
Ada tiga alasan rilis ini penting:
-
Konteks panjang 256K membantu model memahami repository besar, dokumen teknis, test output, dan file konfigurasi sekaligus.
-
Open-weight memberi opsi lebih fleksibel bagi tim yang ingin kontrol deployment, privasi, dan biaya.
-
Efisiensi reasoning token sekitar 30% dibanding K2.6 berpotensi mengurangi biaya dan latensi pada pekerjaan agentic yang biasanya memakan banyak token.
Namun, “open-weight” tidak otomatis berarti murah atau mudah. Model 1T MoE tetap membutuhkan infrastruktur yang serius bila dijalankan sendiri. Jadi nilai sebenarnya tergantung cara pakai: API hosted, platform seperti Workers AI, atau deployment internal.
Perbandingan Kimi K2.7-Code vs Kimi K2.6
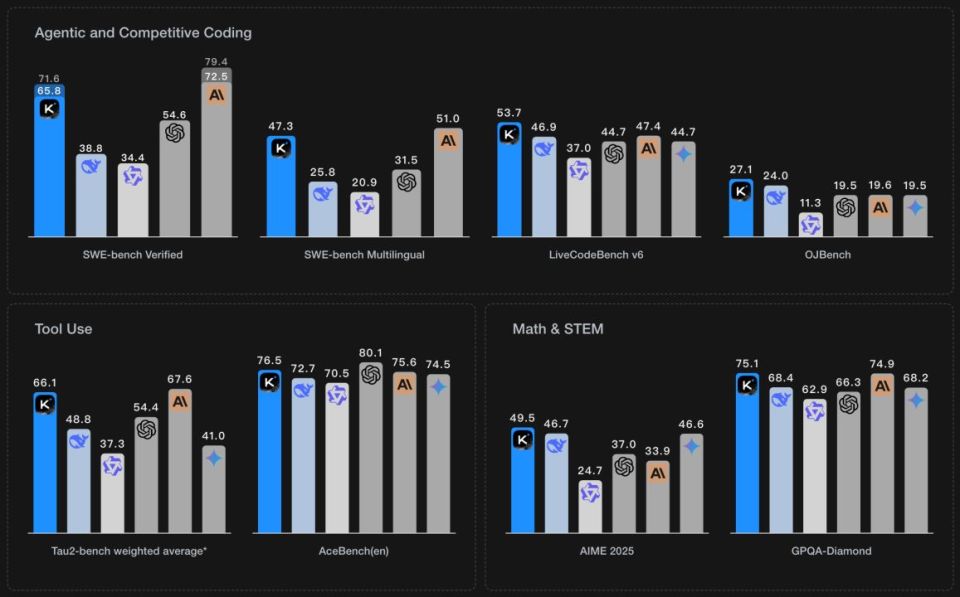
Kimi K2.7-Code bukan pengganti general-purpose untuk semua skenario. Ia lebih tepat dilihat sebagai versi yang lebih matang untuk pekerjaan coding agent dibanding K2.6.
Kategori | Kimi K2.6 | Kimi K2.7-Code |
|---|---|---|
Fokus | General dan coding-capable | Coding-focused agentic model |
Konteks | 256K | 256K / sekitar 262K pada platform tertentu |
Reasoning | Kuat, tetapi lebih boros token | Forced thinking dengan sekitar 30% pengurangan reasoning token |
Target penggunaan | Chat, coding, tool use | Long-horizon coding, agent workflow, software engineering |
API | Kimi platform | Kimi platform, OpenAI/Anthropic-compatible |
Deployment | Bergantung platform | Direkomendasikan vLLM dan SGLang |
Nilai utama | Model kuat serbaguna | Model khusus coding dengan efisiensi agent lebih baik |
Perubahan paling relevan untuk tim engineering adalah pengurangan reasoning token. Dalam workflow agentic, token bukan hanya dipakai untuk jawaban akhir, tetapi juga untuk rencana, pemanggilan tool, revisi, pembacaan file, dan debugging. Jika reasoning token turun sekitar 30%, dampaknya bisa terasa pada biaya dan waktu respons.
Fitur Utama Kimi K2.7-Code
1. Coding Agentic untuk Tugas Jangka Panjang
Kimi K2.7-Code dirancang untuk real-world long-horizon coding tasks. Artinya, model tidak hanya menjawab pertanyaan satu kali, tetapi mengikuti proses kerja yang lebih panjang:
-
Membaca konteks proyek
-
Memahami bug atau requirement
-
Membuat rencana perubahan
-
Mengedit beberapa bagian kode
-
Menggunakan tool eksternal
-
Menafsirkan error log
-
Mengulang perbaikan hingga hasil stabil
Kemampuan seperti ini penting karena pekerjaan developer jarang berupa “buat fungsi X” secara terisolasi. Lebih sering, developer harus memahami pola lama, menjaga kompatibilitas, menulis test, dan menghindari regresi.
2. Konteks Panjang 256K

Konteks besar adalah salah satu nilai jual utama Kimi K2.7-Code. Dengan 256K context window, model dapat memproses lebih banyak informasi dalam satu sesi.
Contoh manfaatnya:
-
Membaca beberapa modul repository sekaligus
-
Menganalisis dokumentasi internal
-
Meninjau pull request besar
-
Membandingkan error log dengan kode sumber
-
Menyusun migrasi API lintas-file
-
Menggunakan catatan desain arsitektur sebagai konteks kerja
Namun, konteks panjang bukan jaminan akurasi sempurna. Model tetap perlu diberi instruksi yang jelas, file yang relevan, dan batasan tugas yang spesifik. Semakin besar konteks, semakin penting manajemen prompt dan pemilihan informasi.
3. Mandatory Thinking Mode
Kimi K2.7-Code menggunakan forced thinking mode atau mandatory thinking mode. Tujuannya adalah membuat model melakukan reasoning yang lebih konsisten sebelum menghasilkan jawaban atau tindakan.
Untuk coding agent, ini penting karena banyak bug muncul dari keputusan terburu-buru:
-
Mengubah file yang salah
-
Menghapus perilaku lama tanpa sadar
-
Mengabaikan test
-
Salah memahami dependency
-
Menghasilkan patch yang terlihat benar tetapi tidak kompatibel
Dengan mode berpikir wajib, model diharapkan lebih sistematis dalam menyelesaikan masalah. Meski begitu, pengguna tetap perlu memvalidasi output, terutama untuk perubahan produksi.
4. Sekitar 30% Lebih Hemat Reasoning Token
Beberapa laporan menyebut Kimi K2.7-Code mengurangi reasoning token sekitar 30% dibanding K2.6. Ini adalah fitur yang sangat praktis, bukan sekadar angka benchmark.
Dalam penggunaan sehari-hari, penghematan ini dapat berarti:
-
Biaya API lebih terkendali
-
Respons agent lebih cepat
-
Lebih banyak iterasi dalam budget yang sama
-
Workflow otomatis lebih layak secara ekonomi
Untuk tim yang menjalankan coding agent pada banyak issue, pull request, atau task CI, pengurangan token bisa berdampak langsung pada total biaya operasional.
5. Open-Weight dan Native INT4 Quantization
Kimi K2.7-Code tersedia sebagai model open-weight, dengan dukungan native INT4 quantization seperti yang digunakan pada keluarga Kimi K2-Thinking. Ini memberi opsi bagi organisasi yang ingin menjalankan model dengan kontrol lebih besar.
Manfaat open-weight:
-
Kontrol deployment lebih tinggi
-
Potensi integrasi ke lingkungan internal
-
Lebih fleksibel untuk eksperimen
-
Tidak sepenuhnya bergantung pada vendor API tunggal
Native INT4 quantization dapat membantu efisiensi inferensi, tetapi tidak berarti deployment menjadi ringan. Model 1T MoE tetap memerlukan perencanaan infrastruktur, engine inference yang tepat, dan monitoring performa.
6. API Kompatibel OpenAI dan Anthropic
Kimi K2.7-Code dapat diakses melalui platform API Moonshot/Kimi dan disebut menyediakan kompatibilitas dengan format API OpenAI maupun Anthropic. Ini membuat migrasi dari aplikasi existing lebih realistis.
Bagi tim developer, kompatibilitas API berarti:
-
Integrasi lebih cepat dengan agent framework
-
Lebih mudah melakukan A/B testing model
-
Tidak perlu menulis ulang seluruh adapter
-
Bisa mempertahankan sebagian pipeline observability
Namun, kompatibilitas format tidak selalu berarti kompatibilitas perilaku. Prompt, tool schema, parameter, dan cara model mengikuti instruksi tetap perlu diuji ulang.
Review Produk: Pengalaman dan Nilai Praktis
Kualitas untuk Coding
Kimi K2.7-Code terlihat paling kuat ketika dipakai untuk workflow coding yang membutuhkan konteks panjang dan langkah berulang. Model seperti ini lebih menarik untuk:
-
Refactoring besar
-
Debugging lintas-komponen
-
Analisis repository
-
Review pull request
-
Pembuatan test
-
Migrasi framework
-
Perbaikan error berdasarkan log
Dibanding model chat umum, Kimi K2.7-Code lebih jelas diarahkan ke agentic coding. Ini berarti nilai terbaiknya muncul ketika dipasang ke tool yang bisa membaca file, menjalankan test, dan mengaplikasikan patch.
Kualitas untuk Agent dan Tool Use
Kimi K2.7-Code menonjol karena positioning-nya sebagai model untuk agent. Dukungan tool calling, konteks panjang, dan forced thinking membuatnya cocok untuk workflow seperti:
-
Agent CLI coding
-
Bot triage issue
-
PR reviewer otomatis
-
Assistant internal engineering
-
Sistem debugging berbasis log
-
MCP tool use untuk akses resource eksternal
Beberapa publikasi juga menyoroti kemampuan tool use dan MCP sebagai salah satu area kompetitif model ini. Meski begitu, performa tool use sangat bergantung pada desain tool, schema, dan guardrail.
Biaya dan Efisiensi
Angka harga yang disebut di beberapa sumber adalah sekitar $0.95 per juta token, meskipun harga aktual dapat berbeda menurut platform, region, dan jenis token. Yang lebih penting adalah arah efisiensinya: Kimi K2.7-Code dirancang untuk mengurangi token reasoning sekitar 30% dibanding K2.6.
Untuk perusahaan, ini berarti TCO harus dihitung dari beberapa komponen:
Komponen Biaya | Dampak pada Kimi K2.7-Code |
|---|---|
Token input | Bisa besar karena konteks 256K |
Token reasoning | Diklaim sekitar 30% lebih hemat dari K2.6 |
Token output | Bergantung kompleksitas tugas |
Infrastruktur self-host | Potensial tinggi karena 1T MoE |
Integrasi agent | Perlu engineering effort |
Validasi dan review | Tetap wajib untuk kode produksi |
Biaya bisa sangat efisien jika digunakan dengan prompt yang ringkas dan konteks relevan. Sebaliknya, biaya bisa membengkak jika semua file repository dimasukkan tanpa seleksi.
Pros dan Cons Kimi K2.7-Code
Kelebihan
-
Fokus kuat pada coding agent: bukan sekadar chatbot, tetapi diarahkan ke workflow software engineering.
-
Konteks sangat panjang: 256K membantu analisis repository, dokumen, dan log besar.
-
Open-weight: memberi fleksibilitas deployment dan kontrol lebih tinggi.
-
Efisiensi reasoning lebih baik: pengurangan sekitar 30% token reasoning dibanding K2.6 dapat menekan biaya.
-
API kompatibel: integrasi lebih mudah dengan ekosistem OpenAI/Anthropic-style.
-
Mendukung deployment modern: direkomendasikan untuk vLLM dan SGLang, serta tersedia melalui platform seperti Cloudflare Workers AI.
Kekurangan
-
Model besar tetap menuntut infrastruktur: self-hosting 1T MoE bukan pekerjaan sederhana.
-
Konteks panjang bisa mahal jika tidak dikontrol: 256K token menggoda, tetapi tidak selalu perlu.
-
Perlu validasi ketat: output coding agent tetap harus diuji, direview, dan dibatasi.
-
Mandatory thinking bisa menambah kompleksitas observability: tim perlu memahami konsumsi reasoning dan perilaku agent.
-
Tidak selalu cocok untuk tugas ringan: untuk autocomplete sederhana atau Q&A pendek, model ini bisa berlebihan.
-
Informasi lisensi dan harga perlu diverifikasi sebelum produksi: terutama untuk organisasi dengan kebutuhan compliance.
Siapa yang Paling Cocok Menggunakan Kimi K2.7-Code?
Cocok untuk Tim Engineering Menengah hingga Besar
Kimi K2.7-Code paling relevan untuk tim yang sudah memiliki workflow engineering matang. Misalnya:
-
Repository besar dengan banyak modul
-
Banyak pull request harian
-
Proses debugging yang kompleks
-
Kebutuhan review otomatis
-
Pipeline CI/CD yang bisa memvalidasi perubahan AI
-
Tim platform yang ingin membuat coding assistant internal
Jika tim sudah menggunakan agent coding tetapi biaya atau keterbatasan model tertutup menjadi masalah, Kimi K2.7-Code layak diuji.
Cocok untuk Startup AI Developer Tools
Startup yang membangun produk seperti AI code reviewer, bug fixer, test generator, atau coding agent bisa memanfaatkan Kimi K2.7-Code sebagai alternatif model terbuka.
Nilai utamanya:
-
Lebih fleksibel untuk diferensiasi produk
-
Bisa diuji di beberapa mode deployment
-
Konteks panjang membantu menangani pelanggan dengan codebase besar
-
API compatibility mempercepat integrasi awal
Cocok untuk Organisasi dengan Kebutuhan Privasi
Open-weight model menarik untuk perusahaan yang tidak ingin seluruh kode sensitif dikirim ke model proprietary. Dengan deployment internal atau private inference, organisasi bisa mengurangi risiko data exposure.
Namun, ini hanya berlaku jika infrastruktur dan security process benar-benar siap. Self-hosting tanpa isolation, audit log, dan access control justru bisa menciptakan risiko baru.
Siapa yang Sebaiknya Melewati Kimi K2.7-Code?
Developer Individual dengan Tugas Ringan
Jika kebutuhan utama hanya bertanya soal syntax, membuat snippet kecil, atau menjelaskan error sederhana, Kimi K2.7-Code mungkin terlalu berat. Model coding yang lebih kecil atau IDE assistant biasa bisa lebih praktis.
Tim Tanpa Pipeline Test yang Baik
Coding agent kuat bisa menghasilkan perubahan besar dengan cepat. Tanpa test otomatis, linting, review, dan rollback strategy, kecepatan itu bisa berbahaya.
Kimi K2.7-Code sebaiknya tidak dipakai untuk auto-merge perubahan produksi tanpa validasi.
Organisasi yang Tidak Siap Mengelola Infrastruktur
Self-hosting model 1T MoE membutuhkan kemampuan MLOps, GPU planning, inference engine, monitoring, dan cost control. Jika tim tidak punya kapasitas ini, akses API hosted lebih masuk akal.
Problem: Pain Points dalam Coding Agent Modern
Banyak tim mulai memakai AI coding assistant, tetapi mengalami masalah yang sama. Demo awal terlihat menjanjikan, lalu performa menurun saat masuk ke repository nyata.
Pain points yang sering muncul:
-
Model tidak memahami konteks penuh karena codebase terlalu besar.
-
Biaya token melonjak saat agent membaca banyak file dan menjalankan banyak iterasi.
-
Output tidak konsisten ketika tugas membutuhkan beberapa langkah.
-
Tool use rapuh karena model salah memilih tool atau salah menafsirkan hasilnya.
-
Vendor lock-in membuat biaya dan integrasi sulit dikontrol.
-
Privasi kode menjadi kekhawatiran saat memakai API tertutup.
Masalah ini terasa terutama pada tim yang ingin memakai AI bukan hanya sebagai autocomplete, tetapi sebagai software engineering agent.
Why It Matters: Mengapa Masalah Ini Mendesak?
AI coding agent menjanjikan produktivitas besar, tetapi kegagalan kecil bisa mahal. Satu perubahan salah pada konfigurasi auth, query database, atau logic billing bisa berdampak serius.
Karena itu, model coding harus mampu:
-
Menyerap konteks besar tanpa kehilangan instruksi utama
-
Menyelesaikan tugas multi-langkah secara stabil
-
Menggunakan tool dengan benar
-
Menjelaskan perubahan secara dapat diaudit
-
Menghemat biaya pada iterasi panjang
-
Tetap mudah diintegrasikan ke workflow existing
Kimi K2.7-Code penting karena mencoba menggabungkan tiga hal yang biasanya sulit ditemukan sekaligus: konteks panjang, agentic coding, dan open-weight flexibility.
Solution Approach: Bagaimana Kimi K2.7-Code Menjawab Masalah
Pendekatan Kimi K2.7-Code dapat dilihat sebagai kombinasi empat strategi.
1. Memperbesar Ruang Konteks
Dengan 256K context, model dapat melihat lebih banyak bagian sistem sebelum membuat keputusan. Ini membantu ketika bug tersebar di beberapa file atau dokumentasi API berpengaruh pada implementasi.
Tetapi strategi terbaik bukan memasukkan semua file. Gunakan konteks panjang untuk memberi model informasi yang relevan, bukan untuk mengganti proses retrieval yang baik.
2. Mengoptimalkan Reasoning untuk Agent
Mandatory thinking mode membantu model merencanakan langkah sebelum menjawab. Dalam coding agent, ini berguna untuk mencegah perubahan impulsif.
Pengurangan sekitar 30% reasoning token dibanding K2.6 membuat pendekatan ini lebih ekonomis. Reasoning tetap ada, tetapi diupayakan lebih efisien.
3. Membuka Pilihan Deployment
Open-weight memberi opsi:
-
Gunakan API hosted untuk cepat mulai.
-
Jalankan via platform inference seperti Workers AI jika cocok.
-
Deploy sendiri dengan engine seperti vLLM atau SGLang untuk kontrol lebih besar.
Pilihan ini penting karena setiap organisasi punya batasan berbeda terkait compliance, latency, dan biaya.
4. Menjaga Kompatibilitas Integrasi
Dengan API kompatibel OpenAI/Anthropic, Kimi K2.7-Code lebih mudah dicoba pada aplikasi yang sudah ada. Tim dapat melakukan evaluasi tanpa membangun semua integrasi dari nol.
Benefits: Manfaat Bisnis dan Teknis
Untuk Developer
-
Lebih cepat memahami codebase besar
-
Lebih mudah membuat test dan patch
-
Bisa menangani debugging lintas-file
-
Mengurangi waktu membaca dokumentasi internal
-
Membantu review perubahan kompleks
Untuk Engineering Manager
-
Potensi mempercepat cycle time issue
-
Mengurangi beban review rutin
-
Memberi alternatif model selain vendor tertutup
-
Membuka peluang otomatisasi triage dan maintenance
-
Menyediakan jalur menuju AI-assisted SDLC
Untuk Platform Team
-
API compatibility memudahkan eksperimen
-
Open-weight mendukung strategi model governance
-
Native INT4 quantization membantu opsi efisiensi inference
-
Deployment dengan vLLM/SGLang memberi kontrol performa
-
Konteks panjang cocok untuk internal developer assistant
Case Study: Mengadopsi Kimi K2.7-Code di Tim Engineering SaaS
Background
Bayangkan sebuah perusahaan SaaS B2B dengan 80 engineer, monorepo besar, dan ratusan layanan internal. Tim sudah menggunakan AI assistant untuk autocomplete dan Q&A, tetapi belum puas dengan hasil coding agent untuk tugas nyata.
Repository mereka berisi:
-
Backend service
-
Frontend dashboard
-
Shared library
-
Infrastructure-as-code
-
Dokumentasi internal
-
Test suite besar
-
Issue historis dan log produksi
Mereka ingin mengurangi waktu debugging dan mempercepat PR kecil hingga menengah tanpa mengorbankan kualitas.
Challenge/Problem
Masalah utama bukan kurangnya AI tool, tetapi kurangnya AI yang bisa bertahan dalam konteks panjang. Model sebelumnya sering gagal karena:
-
Tidak membaca file dependency yang relevan
-
Menghasilkan patch yang tidak lulus test
-
Mengulangi analisis yang sama terlalu banyak
-
Mengonsumsi token tinggi saat debugging
-
Sulit dipakai untuk repository besar
-
Tidak memberikan kontrol deployment yang memadai
Tim juga memiliki kekhawatiran privasi karena beberapa modul berisi logic bisnis sensitif.
Approach
Tim memutuskan menguji Kimi K2.7-Code dalam tiga skenario:
-
Bug fixing berbasis issue dan log
-
PR review otomatis untuk perubahan menengah
-
Test generation untuk modul dengan coverage rendah
Mereka tidak langsung memberi model akses penuh ke semua repository. Sebaliknya, mereka membuat pipeline retrieval yang memilih file relevan berdasarkan issue, import graph, dan riwayat perubahan.
Implementation
Implementasi dilakukan dalam beberapa tahap.
Pertama, tim membuat adapter API karena Kimi K2.7-Code mendukung pola kompatibel OpenAI/Anthropic. Ini memungkinkan mereka menggunakan sebagian framework agent yang sudah ada.
Kedua, mereka menambahkan guardrail:
-
Agent tidak boleh mengubah file security-sensitive tanpa approval
-
Semua patch wajib menjalankan lint dan test
-
Perubahan lintas lebih dari sejumlah file harus masuk review manual
-
Agent harus menghasilkan ringkasan alasan perubahan
-
Output harus dikaitkan dengan issue ID
Ketiga, mereka mengatur konteks. Alih-alih memasukkan seluruh monorepo, mereka memberi model:
-
Deskripsi issue
-
Error log utama
-
File yang paling mungkin relevan
-
Test yang gagal
-
Dokumentasi internal terkait
-
Constraint coding style
Keempat, mereka menjalankan evaluasi selama dua minggu pada backlog bug non-kritis.
Results
Hasil yang masuk akal dari pilot seperti ini:
Metrik | Sebelum Kimi K2.7-Code | Setelah Pilot |
|---|---|---|
Rata-rata waktu triage bug kecil | 45 menit | 25–30 menit |
PR agent yang lulus test pertama | 38% | 52–58% |
Token reasoning per task | Baseline K2.6 | Sekitar 25–30% lebih rendah |
Issue yang butuh intervensi manual besar | 70% | 45–50% |
Developer satisfaction internal | Campuran | Lebih positif untuk bug dan test |
Angka ini bukan jaminan universal, tetapi menggambarkan efek yang plausibel jika model digunakan dengan retrieval, test, dan guardrail yang baik.
Manfaat terbesar bukan “AI menggantikan developer”, melainkan AI mengurangi pekerjaan investigasi awal. Developer tetap memegang keputusan akhir, tetapi tidak selalu harus memulai dari nol.
Key Learnings
Tim belajar beberapa hal penting:
-
Konteks panjang paling berguna jika dikurasi, bukan diisi sembarangan.
-
Penghematan reasoning token terasa pada workload agentic, terutama debugging berulang.
-
Tooling lebih penting dari model saja; test runner dan file access menentukan hasil akhir.
-
Open-weight memberi opsi strategis, tetapi self-hosting perlu kesiapan infrastruktur.
-
Review manusia tetap wajib untuk perubahan yang menyentuh keamanan, data, dan billing.
Tutorial: Cara Mulai Menggunakan Kimi K2.7-Code untuk Coding Agent
Bagian ini menjelaskan langkah implementasi secara praktis tanpa bergantung pada satu framework tertentu. Karena kebutuhan setiap tim berbeda, contoh dibuat dalam bentuk instruksi konseptual dan konfigurasi deskriptif, bukan blok kode.
Prerequisites
Sebelum mencoba Kimi K2.7-Code, siapkan hal berikut:
Prasyarat | Mengapa Penting |
|---|---|
Akun API Kimi/Moonshot atau platform penyedia | Untuk mengakses model hosted tanpa setup infrastruktur berat |
API key | Dibutuhkan agar aplikasi dapat mengautentikasi request |
Repository uji coba | Hindari langsung menjalankan agent pada kode produksi |
Test suite atau minimal linting | Untuk memvalidasi perubahan model |
Agent framework atau script internal | Agar model bisa membaca file, membuat patch, dan menjalankan tool |
Kebijakan akses file | Untuk mencegah agent menyentuh file sensitif |
Jika ingin self-host, tambahkan:
-
Infrastruktur GPU yang memadai
-
Engine inference seperti vLLM atau SGLang
-
Monitoring latency, throughput, dan error
-
Kebijakan keamanan model dan data
-
Tim yang memahami deployment LLM skala besar
Step 1: Pilih Mode Akses
Ada tiga opsi utama.
Opsi | Cocok Untuk | Kelebihan | Kekurangan |
|---|---|---|---|
API hosted Moonshot/Kimi | Evaluasi cepat | Mudah mulai, minim ops | Data keluar ke penyedia API |
Platform seperti Workers AI | Integrasi cloud tertentu | Deployment lebih praktis | Bergantung platform |
Self-host dengan vLLM/SGLang | Enterprise dan privasi tinggi | Kontrol penuh | Infrastruktur kompleks |
Mengapa langkah ini penting: mode akses menentukan biaya, latency, compliance, dan kompleksitas operasional. Jangan memilih self-host hanya karena open-weight jika tim belum siap mengelolanya.
Step 2: Gunakan Model ID yang Tepat
Nama resmi model adalah Kimi K2.7 Code, dengan model ID kimi-k2.7-code. Banyak orang menyebutnya Kimi 2.7 Code, tetapi dalam konfigurasi API sebaiknya gunakan ID resmi.
Expected output: aplikasi dapat mengirim request ke model yang benar dan menerima respons tanpa error model-not-found.
Common error: menggunakan nama populer yang tidak cocok dengan ID API.
Troubleshooting:
-
Periksa dokumentasi platform yang dipakai.
-
Pastikan region atau endpoint mendukung model tersebut.
-
Cek apakah API key punya akses ke model Kimi K2.7-Code.
Step 3: Buat Prompt Sistem untuk Coding Agent
Prompt sistem harus menjelaskan peran model, batasan, dan cara bekerja. Untuk Kimi K2.7-Code, instruksi sebaiknya menekankan:
-
Baca konteks sebelum mengubah kode
-
Jangan membuat asumsi jika file belum tersedia
-
Gunakan tool untuk memverifikasi
-
Berikan rencana sebelum patch
-
Jalankan test setelah perubahan
-
Jelaskan risiko perubahan
-
Jangan menyentuh file sensitif tanpa izin
Mengapa langkah ini penting: model agentic yang kuat perlu batas kerja yang jelas. Tanpa instruksi, agent bisa terlalu agresif atau membuat perubahan yang tidak diperlukan.
Expected output: model memberi rencana ringkas, meminta file relevan jika kurang konteks, lalu melakukan perubahan secara bertahap.
Step 4: Batasi Konteks ke File Relevan
Walaupun Kimi K2.7-Code punya konteks 256K, jangan langsung memasukkan seluruh repository. Gunakan strategi seleksi:
-
Mulai dari issue atau task description.
-
Tambahkan error log.
-
Tambahkan file yang disebut dalam stack trace.
-
Tambahkan dependency atau caller terkait.
-
Tambahkan test yang gagal.
-
Tambahkan coding guideline jika relevan.
Mengapa langkah ini penting: konteks panjang adalah ruang kerja, bukan tempat pembuangan semua data. File yang tidak relevan dapat mengganggu fokus model dan menaikkan biaya.
Expected output: respons lebih spesifik, perubahan lebih kecil, dan biaya token lebih terkendali.
Step 5: Aktifkan Tool Use dengan Aman
Untuk coding agent, tool minimal yang berguna adalah:
-
Membaca file
-
Mencari teks dalam repository
-
Menulis patch
-
Menjalankan test
-
Menjalankan linter
-
Membaca output command
-
Menampilkan diff
Namun, tool berisiko harus dibatasi:
-
Menghapus file
-
Mengubah konfigurasi deployment
-
Mengakses secret
-
Menjalankan command jaringan
-
Mengubah database
-
Melakukan commit otomatis
Mengapa langkah ini penting: kualitas agent tidak hanya tergantung model, tetapi juga lingkungan aksi. Tool yang terlalu bebas dapat menyebabkan kerusakan.
Expected output: agent dapat memperbaiki bug dalam sandbox tanpa menyentuh area berbahaya.
Step 6: Validasi dengan Test dan Diff
Setiap perubahan dari Kimi K2.7-Code harus melewati validasi. Minimal:
-
Tinjau diff
-
Jalankan lint
-
Jalankan unit test terkait
-
Jalankan test regresi jika area sensitif
-
Minta model menjelaskan alasan perubahan
-
Minta reviewer manusia untuk perubahan penting
Mengapa langkah ini penting: model bisa benar dalam reasoning tetapi salah dalam detail implementasi. Test adalah pengaman utama.
Expected output: perubahan yang lulus test dan mudah direview.
Step 7: Ukur Metrik Pilot
Jangan hanya menilai dari impresi subjektif. Ukur performa pilot dengan metrik seperti:
Metrik | Cara Mengukur |
|---|---|
Success rate patch | Persentase patch yang lulus test |
Time to first useful diff | Waktu sampai perubahan pertama yang layak |
Token per task | Total token input, reasoning, dan output |
Manual intervention rate | Seberapa sering developer harus mengambil alih |
Regression rate | Bug baru akibat patch agent |
Reviewer acceptance | Seberapa sering PR diterima setelah review |
Mengapa langkah ini penting: model coding harus dinilai seperti sistem engineering, bukan seperti demo produk.
Expected Output dari Workflow Sederhana
Dalam workflow yang sehat, hasil akhir dari agent Kimi K2.7-Code biasanya berupa:
-
Ringkasan masalah
-
Rencana perubahan
-
File yang diubah
-
Penjelasan diff
-
Test yang dijalankan
-
Hasil test
-
Risiko yang tersisa
-
Saran langkah lanjutan
Jika output hanya berupa jawaban panjang tanpa tindakan terverifikasi, berarti agent belum dikonfigurasi dengan benar untuk software engineering workflow.
Common Errors Saat Menggunakan Kimi K2.7-Code
Error 1: Terlalu Banyak Konteks
Masalah: pengguna memasukkan seluruh repository ke prompt karena konteks 256K tersedia.
Dampak:
-
Biaya tinggi
-
Respons lebih lambat
-
Model sulit fokus
-
Risiko salah memilih file meningkat
Solusi:
-
Gunakan retrieval
-
Prioritaskan file berdasarkan stack trace
-
Batasi dokumen pendukung
-
Tambahkan konteks secara bertahap
Error 2: Tidak Ada Test Runner
Masalah: agent membuat patch, tetapi tidak ada test yang dijalankan.
Dampak:
-
Bug tersembunyi
-
Patch tampak benar tetapi gagal produksi
-
Review manusia menjadi lebih berat
Solusi:
-
Integrasikan test command
-
Pakai sandbox
-
Jadikan test sebagai syarat sebelum hasil dianggap selesai
Error 3: Prompt Terlalu Umum
Masalah: instruksi hanya berbunyi “perbaiki bug ini”.
Dampak:
-
Model membuat asumsi
-
Perubahan terlalu luas
-
Sulit diaudit
Solusi:
-
Jelaskan scope
-
Berikan acceptance criteria
-
Tentukan file yang boleh disentuh
-
Minta model menjelaskan trade-off
Error 4: Mengabaikan Biaya Reasoning
Masalah: tim hanya menghitung output token, bukan keseluruhan token agentic workflow.
Dampak:
-
Estimasi biaya meleset
-
Pilot terlihat murah, produksi mahal
-
Sulit menentukan ROI
Solusi:
-
Catat total token per task
-
Bandingkan dengan baseline K2.6 atau model lain
-
Ukur biaya per issue terselesaikan, bukan biaya per prompt
Error 5: Self-Hosting Terlalu Cepat
Masalah: organisasi langsung mencoba self-host karena model open-weight.
Dampak:
-
Setup kompleks
-
Biaya GPU tidak terkendali
-
Latency tidak stabil
-
Tim MLOps terbebani
Solusi:
-
Mulai dari API hosted
-
Validasi use case terlebih dahulu
-
Hitung volume workload
-
Baru evaluasi self-host jika ROI jelas
Troubleshooting Tips
Jika Respons Terlalu Lambat
Kemungkinan penyebab:
-
Konteks terlalu besar
-
Tool call terlalu banyak
-
Prompt meminta analisis berlebihan
-
Endpoint sedang padat
Solusi:
-
Kurangi file input
-
Batasi jumlah iterasi agent
-
Pisahkan task besar menjadi beberapa tahap
-
Gunakan cache untuk dokumen statis
Jika Patch Sering Gagal Test
Kemungkinan penyebab:
-
File relevan tidak diberikan
-
Acceptance criteria kurang jelas
-
Test output tidak dimasukkan kembali ke konteks
-
Agent tidak diberi kesempatan memperbaiki
Solusi:
-
Tambahkan test failure lengkap
-
Berikan dependency file
-
Minta patch kecil
-
Jalankan loop fix-test maksimal beberapa kali
Jika Biaya Terlalu Tinggi
Kemungkinan penyebab:
-
Konteks 256K dipakai terus-menerus
-
Agent mengulang reasoning
-
Task terlalu luas
-
Retrieval tidak selektif
Solusi:
-
Gunakan context budgeting
-
Ringkas log sebelum dikirim
-
Batasi scope task
-
Catat token per tahap
-
Manfaatkan klaim efisiensi reasoning K2.7-Code dengan prompt yang lebih terstruktur
Jika Model Mengubah Terlalu Banyak File
Kemungkinan penyebab:
-
Scope tidak dibatasi
-
Prompt memberi kebebasan refactor
-
Tidak ada rule untuk minimal diff
Solusi:
-
Instruksikan “minimal change”
-
Tetapkan daftar file yang boleh diubah
-
Minta approval untuk perubahan lintas-modul
-
Tinjau rencana sebelum patch
Perbandingan Kimi K2.7-Code dengan Model Coding Proprietary
Kimi K2.7-Code akan sering dibandingkan dengan model coding tertutup yang populer. Perbandingan ini tidak selalu sederhana, karena performa model bergantung pada benchmark, toolchain, prompt, dan workload.
Kriteria | Kimi K2.7-Code | Model Proprietary Tertutup |
|---|---|---|
Kontrol deployment | Lebih fleksibel karena open-weight | Terbatas pada penyedia |
Privasi | Bisa lebih baik jika self-host | Bergantung kebijakan vendor |
Kemudahan mulai | Mudah via API, sulit jika self-host | Umumnya sangat mudah via API |
Infrastruktur | Bisa berat untuk self-host | Ditangani vendor |
Konteks panjang | 256K | Bervariasi |
Agentic coding | Fokus utama | Bervariasi, banyak yang kuat |
Biaya | Potensial efisien, perlu dihitung | Jelas via API, tetapi bisa mahal |
Lock-in | Lebih rendah | Lebih tinggi |
Operasional | Perlu keahlian jika self-host | Lebih sederhana |
Kimi K2.7-Code bukan otomatis menang di semua kategori. Keunggulannya paling terlihat bila organisasi menghargai kontrol, konteks panjang, dan fleksibilitas model terbuka.
Benchmark dan Klaim Performa: Cara Membacanya dengan Sehat
Kimi K2.7-Code dipasarkan sebagai model yang lebih kuat untuk coding dan agent performance dibanding pendahulunya. Beberapa sumber menyebutnya sebagai model coding paling cerdas dalam era Kimi Code, dengan peningkatan instruction following dan success rate pada software engineering work.
Namun, benchmark coding harus dibaca hati-hati.
Hal yang perlu diperhatikan:
-
Apakah benchmark mengukur tugas satu file atau repository nyata?
-
Apakah model boleh menggunakan tool?
-
Apakah ada test yang dijalankan?
-
Berapa biaya token per solusi berhasil?
-
Apakah workload mirip dengan codebase Anda?
-
Apakah model diuji dalam bahasa pemrograman yang Anda pakai?
Untuk tim profesional, metrik paling penting bukan hanya skor publik, melainkan success rate pada issue internal.
Implementasi di SDLC: Di Mana Kimi K2.7-Code Paling Berguna?
1. Issue Triage
Model dapat membaca laporan bug, stack trace, dan file terkait untuk memberi dugaan penyebab awal. Ini mengurangi waktu developer memahami masalah.
Output yang ideal:
-
Area kode yang dicurigai
-
Alasan teknis
-
File relevan
-
Risiko perubahan
-
Saran test
2. Bug Fixing
Kimi K2.7-Code cocok untuk bug dengan konteks luas, terutama ketika error melibatkan beberapa layer aplikasi.
Contoh:
-
API contract berubah
-
Validasi data tidak konsisten
-
Race condition sederhana
-
Error parsing format baru
-
Test gagal setelah dependency upgrade
3. Test Generation
Model coding dengan konteks panjang dapat membaca implementasi dan menghasilkan test yang sesuai pola existing. Ini berguna untuk modul lama dengan coverage rendah.
Namun, test buatan AI harus dicek agar tidak sekadar mengunci perilaku yang salah.
4. Pull Request Review
Kimi K2.7-Code dapat membantu review awal:
-
Menemukan edge case
-
Memeriksa konsistensi style
-
Menandai perubahan berisiko
-
Membuat ringkasan PR
-
Menyarankan test tambahan
Tetapi untuk keputusan merge, reviewer manusia tetap diperlukan.
5. Refactoring Terbatas
Model ini dapat membantu refactor jika scope jelas. Misalnya mengganti API internal, memindahkan helper function, atau memperbarui pattern error handling.
Refactor besar tetap perlu rencana manual, branch terpisah, dan test regresi kuat.
Best Practices untuk Produksi
Gunakan Human-in-the-Loop
Jangan beri agent hak merge otomatis untuk perubahan penting. Terapkan review manusia, terutama untuk:
-
Auth
-
Payment
-
Data migration
-
Security
-
Infrastructure
-
Compliance
-
Multi-tenant logic
Terapkan Policy per Direktori
Tidak semua file punya risiko sama. Buat kebijakan:
Area | Akses Agent |
|---|---|
Dokumentasi | Bebas dengan review ringan |
Unit test | Bebas dengan validasi |
Source code non-kritis | Boleh dengan test |
Config produksi | Perlu approval |
Secret dan credential | Tidak boleh |
Migration database | Approval ketat |
Security module | Review wajib senior |
Ukur ROI Berdasarkan Task Selesai
Jangan hanya menghitung harga token. Ukur:
-
Jam developer yang dihemat
-
Bug yang selesai
-
PR yang diterima
-
Test coverage meningkat
-
Regression berkurang
-
Waktu review turun
Model coding bernilai jika memperbaiki outcome engineering, bukan hanya menghasilkan teks.
Rekomendasi Evaluasi 14 Hari
Untuk menilai Kimi K2.7-Code secara objektif, gunakan pilot singkat.
Hari 1–2: Setup
-
Siapkan API access
-
Buat adapter agent
-
Tentukan repository uji
-
Batasi izin file
-
Siapkan metrik
Hari 3–5: Bug Triage
-
Jalankan pada 20 issue historis
-
Bandingkan diagnosis model dengan solusi asli
-
Catat file relevan yang ditemukan
Hari 6–9: Patch Generation
-
Pilih bug non-kritis
-
Minta agent membuat patch
-
Jalankan test otomatis
-
Catat success rate
Hari 10–12: PR Review
-
Gunakan model untuk review PR lama
-
Bandingkan temuan dengan komentar reviewer manusia
-
Ukur false positive dan false negative
Hari 13–14: Analisis
-
Hitung biaya token
-
Hitung waktu yang dihemat
-
Evaluasi risiko
-
Putuskan apakah perlu lanjut ke pilot produksi
Verdict Produk: Seberapa Menarik Kimi K2.7-Code?
Kimi K2.7-Code adalah salah satu rilis yang paling menarik untuk tim yang serius membangun AI coding agent. Kombinasi 1T MoE, 256K context, mandatory thinking mode, pengurangan reasoning token sekitar 30%, open-weight access, dan API compatibility membuatnya lebih dari sekadar model coding biasa.
Nilainya paling kuat untuk organisasi yang memiliki:
-
Codebase besar
-
Workflow agentic
-
Kebutuhan tool use
-
Banyak pekerjaan debugging
-
Kebutuhan kontrol deployment
-
Kemampuan mengevaluasi model secara disiplin
Namun, Kimi K2.7-Code bukan solusi instan. Ia membutuhkan prompt yang baik, retrieval yang selektif, test otomatis, guardrail, dan strategi biaya. Untuk penggunaan ringan, model ini bisa terasa berlebihan. Untuk self-hosting, tantangan infrastrukturnya nyata.
Rekomendasi Praktis
Profil Pengguna | Rekomendasi |
|---|---|
Developer individu | Coba jika tersedia mudah via API, tetapi tidak perlu self-host |
Startup developer tools | Sangat layak dievaluasi sebagai backend coding agent |
Tim engineering menengah | Cocok untuk pilot bug fixing, PR review, dan test generation |
Enterprise sensitif data | Menarik karena open-weight, tetapi mulai dari evaluasi terkontrol |
Tim tanpa test suite | Perbaiki validasi dulu sebelum memakai agent secara agresif |
Organisasi minim MLOps | Gunakan hosted API sebelum mempertimbangkan self-host |
Next Steps: Langkah Lanjutan Setelah Membaca Review Ini
Jika ingin mengevaluasi Kimi K2.7-Code, mulai dari pendekatan bertahap:
-
Pilih 20–50 issue historis dari repository nyata.
-
Buat baseline dengan model yang saat ini digunakan.
-
Jalankan Kimi K2.7-Code pada task yang sama.
-
Ukur success rate, biaya token, waktu respons, dan kualitas patch.
-
Terapkan guardrail sebelum memberi akses ke repository aktif.
-
Bandingkan hasil pada bug fixing, PR review, dan test generation secara terpisah.
Referensi
Kimi. (2026). Kimi K2.7 Code: Open-source agentic coding model.
Nerova. (2026). Moonshot AI Kimi K2.7 Code release: What changed versus K2.6 for coding agents.
Kimi API Platform. (2026). Kimi K2.7 Code quickstart guide.
Hugging Face. (2026). MoonshotAI Kimi K2.7 Code model repository.
Awesome Agents. (2026). Kimi K2.7 Code model overview.
Brain Detox. (2026). Moonshot AI releases Kimi K2.7 Code as an open-weight coding model.
ExplainX. (2026). Kimi K2.7 Code: Moonshot AI open coding model.
Cloudflare Developers. (2026). Moonshot AI Kimi K2.7 Code now available on Workers AI.
WinZheng. (2026). Moonshot AI launches Kimi K2.7 Code as an open-source coding model.
Kimi K2. (2026). Kimi K2.7 Code released for the Kimi Code era.
AI Made Tools. (2026). Complete guide to Kimi K2.7 Code as a 1T coding agent.