Programming
Cara Cerdas Hemat Token AI Agent dengan Headroom Compression
Kalau kamu lagi ngulik AI agent atau coding assistant kayak Claude Code, Codex, atau Cursor, pasti pernah ngerasain momen "kok tiba-tiba kena limit token" padahal cuma nyuruh dia baca beberapa file. Nah, di sinilah istilah context compression dan tool bernama Headroom mulai rame dibahas. Intinya, Headroom itu semacam "penyaring" yang berdiri di antara agent kamu dan LLM, tugasnya memampatkan tool output, log, potongan RAG, sampai riwayat percakapan sebelum semuanya benar-benar dikirim ke model. Hasilnya, biaya token bisa turun drastis tanpa bikin jawaban jadi ngasal.
Sebelum lanjut, ada satu hal penting yang perlu aku sampaikan biar kamu nggak salah langkah: nama "Headroom" ini dipakai oleh beberapa sumber dengan detail yang agak berbeda-beda, misalnya soal jumlah bintang GitHub (ada yang nyebut 37 ribu, ada yang 29,5 ribu, ada yang cuma "262 bintang bulan ini") dan juga alamat repository yang bervariasi. Jadi sebelum instal apa pun, selalu cek dulu langsung ke halaman resminya dan pastikan kamu instal paket yang publishernya jelas, bukan sekadar ikut-ikutan link pertama yang muncul di hasil pencarian.
Apa Itu Headroom dan Kenapa Context Compression Jadi Penting
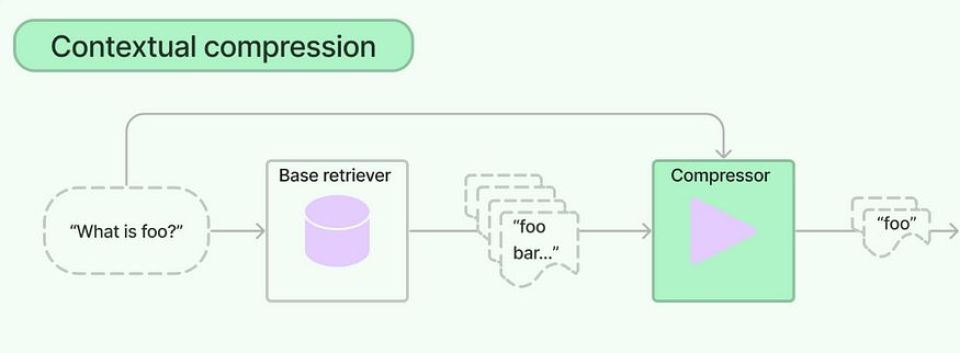
Coba bayangin kamu nyuruh AI agent buka file log server yang isinya ribuan baris, terus minta dia cari baris yang statusnya FATAL. Kalau semua baris itu dikirim mentah-mentah ke model, kamu bakal bayar token untuk baris-baris yang sama sekali nggak penting, padahal yang dibutuhin cuma beberapa baris error saja. Salah satu contoh yang sering dipakai buat menggambarkan masalah ini adalah kasus di mana log sebesar sekitar 10 ribuan token berhasil dipangkas jadi sekitar seribu dua ratusan token saja, dan baris FATAL yang dicari tetap ketemu.
Context compression adalah proses memampatkan data yang masuk ke context window LLM (tool output, log, dokumen RAG, riwayat chat) supaya jumlah token yang dikirim jauh lebih kecil, tapi informasi penting yang dibutuhkan model tetap terjaga.
Headroom mengklaim posisinya sebagai "lapisan" di antara aplikasi atau agent kamu dan penyedia LLM seperti Anthropic, OpenAI, atau Bedrock. Bedanya sama teknik lama seperti truncation (asal potong) atau summarization (diringkas paksa), Headroom katanya menggunakan pendekatan yang lebih terstruktur dan reversible, artinya data aslinya nggak dibuang, cuma "disimpan sementara" dan bisa diambil lagi kalau model benar-benar membutuhkannya.
Kenapa ini penting buat kamu yang pakai AI agent setiap hari? Karena biaya LLM itu dihitung per token, baik token yang masuk maupun token yang keluar. Kalau agent kamu terus-terusan membawa histori percakapan yang gendut plus tool output yang berulang, biaya bulanan bisa membengkak tanpa kamu sadari. Beberapa pengguna bahkan melaporkan pengeluaran harian mereka turun dari sekitar 200 dolar menjadi sekitar 30 dolar setelah memasang layer compression semacam ini, walau angka ini tentu bisa berbeda-beda tergantung pola pemakaian masing-masing.
Masalah yang Sering Dialami Pengguna AI Agent
Beberapa keluhan yang paling sering muncul soal context window ini kira-kira begini:
-
Hasil
grepatau pencarian kode mengembalikan ratusan baris padahal cuma butuh satu fungsi -
File log produksi isinya 95 persen noise operasional, sisanya baru error penting
-
Dokumen RAG yang diambil sering mengulang header, disclaimer, atau boilerplate yang sama
-
Riwayat percakapan yang panjang bikin sesi kena "auto-compact" lebih cepat dari yang diharapkan
-
Kalau pakai beberapa agent sekaligus (Claude Code, Codex, Cursor), masing-masing mulai dari nol, nggak saling berbagi konteks
Kalau kamu ngerasa relate sama poin-poin di atas, artinya kamu memang calon pengguna yang pas buat tool seperti ini.
Cara Kerja Headroom di Balik Layar
Menariknya, Headroom nggak cuma mengandalkan satu trik doang. Dari berbagai penjelasan yang ada, arsitekturnya dipecah jadi beberapa komponen yang masing-masing punya tugas spesifik. Kalau digambarkan secara sederhana, alurnya kira-kira begini:
Agent/App kamu (Claude Code, Cursor, Codex, LangChain, dst)
│ prompt, tool output, log, RAG, file
▼
CacheAligner → ContentRouter → penyimpanan reversible
├─ Kompresor JSON
├─ Kompresor kode (berbasis struktur/AST)
└─ Kompresor teks/prosa
│ prompt yang sudah dipadatkan + tool "ambil data asli"
▼
Penyedia LLM (Anthropic, OpenAI, dst)
ContentRouter bertugas mendeteksi jenis konten yang masuk, apakah itu JSON, kode program, log, atau teks biasa, lalu meneruskannya ke "spesialis" yang tepat. Logikanya sederhana, karena cara memampatkan JSON tentu beda dengan cara memampatkan kode Python.
Kompresor untuk JSON biasanya menyimpan skema data sekali saja, lalu baris-baris berikutnya cuma diwakili nilainya tanpa mengulang nama field yang sama. Nilai yang aneh atau di luar kebiasaan (anomali) tetap dipertahankan, begitu juga item pertama dan terakhir, sementara ratusan baris di tengah yang dianggap kurang relevan disimpan di cache lokal, bukan dihapus permanen.
Kompresor kode memakai pendekatan berbasis struktur kode (mirip AST atau tree-sitter), jadi bukan asal potong baris. Untuk kebutuhan eksplorasi, biasanya cukup ambil signature fungsi, nama kelas, dan import, tanpa perlu badan fungsinya secara utuh. Untuk kasus pencarian kode, hanya bagian yang cocok saja yang ditampilkan lengkap dengan beberapa baris konteks di sekitarnya.
Kompresor teks atau prosa biasanya berbasis model kecil yang dilatih khusus dari data "jejak agent" alias rekaman sesi tool call sungguhan, bukan teks umum dari internet. Tujuannya supaya model itu paham bahwa pesan error itu penting, sementara disclaimer yang berulang-ulang bisa dipadatkan.
CacheAligner perannya agak berbeda, dia nggak fokus mengurangi token tapi menstabilkan bagian awal prompt supaya cache di sisi provider (seperti prompt caching di Anthropic) bisa "kena" terus. Kalau bagian awal prompt kamu berubah-ubah karena ada timestamp atau session ID yang dinamis, cache jadi gampang batal, dan itu bikin biaya naik lagi walau isi konten sebenarnya nggak banyak berubah.
Terakhir, konsep yang paling sering ditonjolkan adalah mekanisme reversible, semacam pola simpan-cache-ambil-kembali. Data asli disimpan lokal dengan kunci unik, lalu model diberi semacam "tool tambahan" yang bisa dipanggil kalau dia butuh detail lengkap dari data yang sudah dipadatkan. Praktiknya, model jarang benar-benar memanggil tool itu karena versi yang dipadatkan sudah cukup informatif, tapi keberadaan jalur ini yang membuat kompresi agresif jadi terasa lebih aman dibanding sekadar diringkas tanpa jejak.
Tutorial: Cara Instalasi dan Pemakaian Headroom
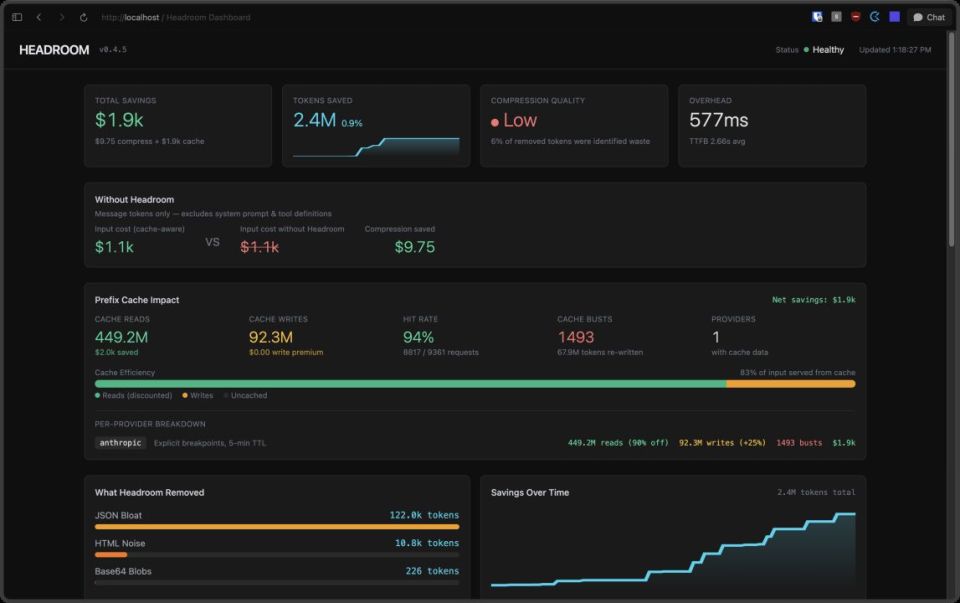
Bagian ini aku bikin selengkap mungkin biar kamu bisa langsung coba sendiri, bukan cuma baca teori. Aku susun step by step lengkap dengan alasan kenapa tiap langkah itu penting, plus beberapa kesalahan umum yang biasa ditemui.
Prasyarat
Sebelum mulai, pastikan beberapa hal ini sudah siap:
-
Python versi 3.10 atau lebih baru, karena beberapa fitur seperti pemrosesan ML butuh versi Python yang cukup baru
-
Node.js kalau kamu mau pakai versi TypeScript/JavaScript-nya
-
Akses ke API key penyedia LLM yang kamu pakai (Anthropic, OpenAI, atau lainnya)
-
Koneksi internet yang stabil, karena beberapa komponen (seperti model kompresi teks) perlu diunduh saat instalasi pertama
-
Sudah familiar dengan penggunaan terminal atau command line dasar
Kenapa prasyarat ini penting? Karena Headroom berjalan sebagai proses lokal di komputer kamu, jadi kompatibilitas versi Python dan ketersediaan resource lokal (RAM, disk) memengaruhi seberapa lancar proses kompresinya nanti.
Langkah 1: Instalasi Paket
Untuk pengguna Python, jalankan:
pip install "headroom-ai[all]"
Kalau kamu cuma butuh fitur tertentu saja supaya instalasi lebih ringan, bisa pakai ekstra yang lebih spesifik:
pip install "headroom-ai[proxy]" # mode proxy saja
pip install "headroom-ai[mcp]" # server MCP saja
pip install "headroom-ai[langchain]" # integrasi LangChain
Untuk pengguna Node.js/TypeScript:
npm install headroom-ai
Kenapa langkah ini penting: memilih ekstra yang sesuai kebutuhan bikin instalasi lebih cepat dan mengurangi risiko konflik dependency, terutama kalau komputer kamu nggak punya resource besar buat menjalankan model machine learning tambahan.
Kesalahan umum: banyak pengguna lupa memakai tanda kutip di sekitar "headroom-ai[all]". Di beberapa shell seperti zsh, tanda kurung siku tanpa kutip bisa dianggap karakter khusus dan bikin instalasi gagal dengan error semacam "no matches found".
Langkah 2: Pilih Mode Pemakaian
Headroom biasanya menawarkan beberapa mode. Pilih salah satu yang paling sesuai kebutuhan kamu.
Mode paling gampang, membungkus agent yang sudah ada:
headroom wrap claude
Kamu juga bisa ganti claude dengan codex, cursor, aider, atau copilot sesuai coding agent yang kamu pakai.
Mode proxy, cocok kalau kamu nggak mau ubah kode apa pun:
headroom proxy --port 8787
Lalu arahkan environment variable aplikasi kamu:
export ANTHROPIC_BASE_URL=http://localhost:8787
Mode library, kalau kamu mau kontrol lebih detail lewat kode:
from headroom import compress
from anthropic import Anthropic
client = Anthropic()
messages = [{"role": "user", "content": teks_yang_panjang}]
result = compress(messages, model="claude-opus-4")
response = client.messages.create(
model="claude-opus-4",
messages=result.messages
)
print("Token yang dihemat:", result.tokens_saved)
Kenapa ini penting: mode wrap cocok kalau kamu cuma butuh solusi cepat tanpa sentuh kode sama sekali. Mode proxy pas buat tim yang aplikasinya sudah berjalan dan nggak mau repot ubah banyak baris kode. Mode library cocok kalau kamu butuh kontrol granular, misalnya cuma mau kompresi bagian tertentu dari prompt.
Langkah 3: Cek Hasil Penghematan
Setelah beberapa kali pemakaian, jalankan:
headroom stats
Output yang diharapkan biasanya berupa ringkasan seperti jumlah token sebelum dan sesudah kompresi, rasio penghematan, dan estimasi biaya yang terhemat berdasarkan harga model yang kamu pakai saat itu.
Kenapa langkah ini penting: tanpa mengukur angka nyatanya, kamu cuma mengandalkan klaim marketing. Dengan menjalankan perintah ini di workload kamu sendiri, kamu bisa tahu persis berapa persen penghematan yang relevan buat kasus kamu, bukan cuma angka generik dari benchmark orang lain.
Langkah 4 (Opsional): Pasang sebagai MCP Server
Kalau kamu memakai klien yang mendukung Model Context Protocol, seperti Claude Desktop atau Cursor, kamu bisa daftarkan Headroom sebagai server MCP:
headroom mcp install
Setelah ini biasanya muncul beberapa tool baru yang bisa dipanggil model, semacam tool untuk memampatkan konten, tool untuk mengambil data asli, dan tool untuk melihat statistik sesi.
Troubleshooting Umum
-
Instalasi gagal dengan error sertifikat (
CERTIFICATE_VERIFY_FAILED) biasanya terjadi kalau kamu berada di jaringan kantor yang memakai SSL inspection. Coba pakai paket versi biner yang sudah dikompilasi, atau pastikan sertifikat root perusahaan sudah terpasang di sistem. -
Proxy tidak terhubung ke agent sering disebabkan environment variable base URL belum benar-benar terbaca oleh proses agent. Pastikan kamu mengekspor variabel itu di sesi terminal yang sama sebelum menjalankan agent-nya.
-
Model kompresi teks lambat saat pertama dijalankan wajar terjadi karena model perlu diunduh dulu dari internet. Setelah unduhan pertama selesai, proses berikutnya biasanya jauh lebih cepat karena sudah tersimpan lokal.
-
Hasil kompresi terasa terlalu agresif sampai kehilangan detail penting kalau ini terjadi, coba manfaatkan fitur pengambilan data asli (retrieval), atau turunkan level agresivitas kompresi kalau tersedia opsinya.
Kelebihan dan Kekurangan Headroom
Supaya kamu bisa menilai secara adil, aku coba rangkum plus minusnya berdasarkan pola yang konsisten muncul di berbagai ulasan.
Kelebihan
-
Berjalan lokal di komputer kamu, jadi data sensitif seperti kode sumber atau log internal nggak perlu dikirim ke pihak ketiga selain penyedia LLM yang memang sudah kamu pakai
-
Mendukung banyak jenis konten sekaligus (JSON, kode, log, teks), bukan cuma satu jenis data tertentu
-
Punya mekanisme untuk mengambil kembali data asli, jadi kompresi nggak sepenuhnya "buang informasi selamanya"
-
Bisa dipasang tanpa mengubah kode aplikasi lewat mode proxy atau mode wrap
-
Mendukung berbagai framework populer seperti LangChain, LiteLLM, dan Vercel AI SDK
Kekurangan
-
Menjalankan proses lokal tambahan berarti butuh sedikit resource ekstra (RAM dan penyimpanan), terutama kalau memakai fitur model machine learning untuk kompresi teks
-
Nggak semua jenis konten bisa dipadatkan sama efektifnya. Untuk eksplorasi codebase yang benar-benar baru, penghematan token biasanya jauh lebih kecil dibanding kasus log atau pencarian kode yang repetitif
-
Butuh sedikit waktu belajar buat memahami mode mana yang paling cocok buat workflow kamu
-
Klaim angka penghematan di berbagai sumber online cenderung nggak konsisten, jadi lebih aman kalau kamu ukur sendiri di workload nyata daripada percaya begitu saja pada satu angka tertentu
-
Kalau environment kerja kamu sangat terbatas (misalnya sandbox yang nggak boleh menjalankan proses lokal atau proxy), tool semacam ini jadi kurang relevan
Siapa yang Cocok Pakai, Siapa yang Sebaiknya Skip
Cocok banget buat kamu kalau:
-
Rutin memakai coding agent seperti Claude Code, Cursor, atau Codex dan mulai merasa biaya tokennya membengkak
-
Sering bekerja dengan log produksi yang panjang atau hasil pencarian kode yang bertele-tele
-
Butuh sesi kerja yang lebih panjang tanpa keburu kena limit context window
-
Peduli soal privasi data dan lebih nyaman kalau pemrosesan tambahan dilakukan lokal, bukan lewat layanan pihak ketiga berbayar
Sebaiknya dipikir ulang atau di-skip dulu kalau:
-
Kamu cuma sesekali chat singkat dengan prompt pendek, di mana context window nggak pernah jadi masalah
-
Environment kerja kamu benar-benar terbatas dan nggak memungkinkan menjalankan proses lokal tambahan
-
Sudah cukup puas dengan fitur bawaan dari provider (seperti prompt caching atau fitur ringkas riwayat percakapan otomatis) dan nggak butuh lapisan tambahan
Perbandingan dengan Pendekatan Lain
Biar lebih jelas posisi Headroom dibanding pendekatan lain yang sering dipakai untuk mengatasi masalah context window, aku susun tabel perbandingan sederhana berikut:
Pendekatan | Cakupan Konten | Bisa Ambil Data Asli Kembali | Butuh Ubah Kode |
|---|---|---|---|
Layer kompresi seperti Headroom | Tool output, log, RAG, kode, riwayat chat | Bisa (lewat mekanisme retrieval) | Tidak wajib |
Fitur ringkas otomatis dari provider | Hanya riwayat percakapan | Umumnya tidak | Tidak |
Kompresi khusus output CLI | Output command line saja | Umumnya tidak | Minim |
Truncation manual (potong manual) | Tergantung implementasi | Tidak | Ya |
Layanan kompresi berbasis cloud pihak ketiga | Teks yang dikirim ke API mereka | Umumnya tidak | Ya |
Kriteria yang Perlu Dipertimbangkan
-
Cakupan jenis data: kalau workload kamu campur-campur antara log, JSON, dan kode, pendekatan yang bisa menangani banyak jenis konten sekaligus jelas lebih efisien dibanding harus pasang beberapa tool terpisah
-
Keamanan data: kalau kamu bekerja dengan data sensitif, pendekatan yang berjalan lokal biasanya lebih aman dibanding mengirim data ke layanan kompresi pihak ketiga
-
Kompatibilitas dengan fitur provider: pastikan pendekatan yang kamu pilih nggak malah mengganggu fitur cache bawaan provider, karena keduanya sebenarnya bisa saling melengkapi kalau dikonfigurasi dengan benar
-
Kemudahan pemasangan: kalau tim kamu nggak punya banyak waktu buat integrasi rumit, mode yang nggak butuh ubah kode jelas lebih menarik
Rekomendasi berdasarkan skenario:
-
Kalau kamu tim kecil yang ingin solusi cepat tanpa banyak konfigurasi, mode wrap atau proxy dari layer kompresi semacam Headroom cukup masuk akal untuk dicoba
-
Kalau kebutuhan kamu cuma soal riwayat percakapan yang kepanjangan, fitur bawaan provider mungkin sudah cukup tanpa perlu tool tambahan
-
Kalau data kamu sangat sensitif dan nggak boleh keluar dari infrastruktur internal sama sekali, pastikan kamu memilih opsi yang benar-benar berjalan lokal, bukan yang mengandalkan API pihak ketiga
Cerita dan Pengalaman Praktis
Dari beberapa laporan pengguna yang beredar, salah satu pola yang paling menarik adalah soal sesi kerja yang jadi jauh lebih panjang. Ada yang bilang sesi kerjanya biasanya cuma tahan sekitar setengah jam sebelum kena limit, terus setelah menambahkan lapisan kompresi macam ini, sesi bisa bertahan sampai beberapa jam dengan context window yang sama besarnya. Ini masuk akal secara teori, karena kalau sebagian besar "sampah" token dari tool output berhasil dipadatkan, sisa kapasitas context window otomatis jadi lebih longgar buat percakapan yang benar-benar produktif.
Tapi ada juga catatan penting dari komunitas yang menurutku wajib kamu perhatikan: penghematan token secara agregat itu belum tentu langsung sama dengan penghematan biaya secara keseluruhan. Kalau prefix prompt kamu terus berubah-ubah sehingga cache di sisi provider gagal "kena", bisa jadi penghematan token yang terlihat di angka statistik nggak benar-benar terasa di tagihan akhir. Jadi saran paling jujur yang bisa aku kasih, jangan cuma percaya angka persentase yang dipajang di halaman marketing, coba dulu di workload nyata kamu sendiri, bandingkan biaya sebelum dan sesudah selama beberapa hari pemakaian normal.
Soal Angka-Angka Benchmark yang Perlu Dibaca dengan Hati-Hati
Ini bagian yang menurutku penting banget buat transparansi. Kalau kamu googling soal tool kompresi context semacam ini, kamu akan nemu banyak angka yang kelihatannya meyakinkan, mulai dari klaim penghematan 60 persen sampai 95 persen, atau angka bintang GitHub yang berbeda-beda tiap sumber. Beberapa hal yang perlu kamu waspadai:
-
Angka penghematan token sangat bergantung pada jenis workload. Kasus log analysis atau pencarian kode biasanya menunjukkan penghematan paling besar, sementara eksplorasi codebase yang benar-benar baru cenderung menunjukkan penghematan paling kecil karena datanya memang belum ada redundansi untuk dipangkas
-
Statistik popularitas seperti jumlah bintang atau fork di GitHub bisa berubah cepat dan sering dilaporkan berbeda-beda antar artikel, jadi jangan jadikan itu satu-satunya alasan buat percaya begitu saja
-
Selalu periksa alamat repository resminya sebelum instalasi. Nama tool yang sedang populer kadang dipakai ulang oleh pihak lain untuk membuat paket serupa dengan nama mirip-mirip, jadi pastikan kamu mengunduh dari sumber yang benar-benar terverifikasi, misalnya lewat halaman dokumentasi resmi atau publisher paket yang jelas identitasnya di PyPI atau npm
-
Klaim soal "tidak ada penurunan akurasi" sebaiknya dianggap sebagai hasil dari pengujian benchmark tertentu, bukan garansi mutlak buat semua jenis pertanyaan atau workload kamu sendiri
Sikap yang paling sehat adalah menganggap semua angka ini sebagai indikasi awal, bukan kepastian. Uji sendiri di kasus pemakaian kamu, lihat apakah hasil jawabannya tetap konsisten, dan pantau tagihan LLM kamu selama beberapa minggu pemakaian normal sebelum benar-benar bergantung penuh ke tool semacam ini untuk pekerjaan yang kritikal.
Studi Kasus: Simulasi Tim Kecil yang Pindah ke Headroom
Biar nggak cuma teori, coba mughu ceritain gambaran skenario yang biasa dilaporkan tim-tim kecil yang mulai serius pakai layer kompresi semacam Headroom. Anggap saja ada startup dengan tiga orang engineer, mereka pakai Claude Code buat ngerjain refactor besar-besaran di codebase lama yang isinya ratusan ribu baris kode. Sebelum kenal context compression, pola kerjanya kira-kira begini: buka file, minta agent baca seluruh isi file, terus lanjut ke file berikutnya. Kedengarannya biasa, tapi kalau file-nya gede dan agent harus bolak-balik baca ulang buat ngerti konteks, token yang terpakai numpuk cepat banget.
Nah, waktu mereka pasang mode proxy dari Headroom di depan koneksi ke Anthropic, hal pertama yang keliatan bukan langsung dari tagihan, tapi dari lamanya sesi kerja. Biasanya sesi cuma tahan sekitar tiga puluh menitan sebelum context window penuh dan kena auto-compact, sekarang bisa jalan berjam-jam tanpa keluhan berarti. Kenapa bisa gitu? Karena setiap kali agent minta baca file besar atau grep di seluruh folder, hasilnya udah dipadatkan lebih dulu sebelum masuk ke prompt yang dikirim ke model. Bagian yang berulang atau nggak relevan ditahan di cache lokal, jadi context window nggak cepat penuh sama sampah token.
Yang menarik, tim ini juga sempat mengalami momen di mana kompresi kelewat agresif buat satu kasus spesifik: mereka nyuruh agent nyari bug di file konfigurasi YAML yang isinya campuran struktur bertingkat. Awalnya hasil yang dipadatkan bikin agent salah nebak baris mana yang bermasalah, soalnya indentasi penting yang jadi ciri khas YAML ikut terpangkas kompresor JSON generik. Solusinya, mereka manfaatkan fitur retrieval buat ambil kembali versi asli file itu, terus melaporkan kejadian ini biar dipertimbangkan buat perbaikan di kompresor versi berikutnya. Poinnya di sini, mekanisme reversible itu bukan cuma pajangan marketing, tapi memang kepake di situasi nyata waktu kompresi bikin informasi penting ikut kepotong.
Dari sisi biaya, laporan yang sering muncul memang variatif, tapi pola umumnya konsisten: penghematan paling kentara justru ada di pekerjaan yang berulang-ulang, kayak menjalankan test suite yang sama berkali-kali, atau nge-debug error yang sama dengan log yang mirip-mirip setiap kali dijalankan. Sebaliknya, waktu tim ini mengerjakan fitur benar-benar baru dari nol, penghematannya nggak sebesar itu, soalnya belum ada pola berulang yang bisa dipadatkan. Ini jadi pelajaran penting: jangan berharap penghematan token bakal seragam di semua jenis pekerjaan, karena karakteristik datanya beda-beda.
Pelajaran yang Bisa Diambil dari Simulasi Ini
Beberapa hal yang layak jadi catatan buat teman-teman yang mau nyoba pola serupa di tim sendiri:
-
Jangan langsung pasang mode paling agresif di hari pertama. Mulai dari level kompresi standar, pantau dulu apakah hasil kerja agent masih akurat, baru naikkan agresivitasnya kalau memang aman
-
Siapkan kebiasaan buat cek
headroom statssecara rutin, minimal seminggu sekali, biar teman-teman punya data nyata buat dibandingkan sebelum dan sesudah -
Kalau ada kasus di mana hasil kompresi bikin jawaban jadi ngasal atau nggak akurat, jangan buru-buru nyalahin tool-nya. Coba cek dulu apakah jenis data yang dipakai memang cocok sama compressor yang aktif, soalnya beberapa format data punya karakteristik unik seperti YAML tadi
-
Dokumentasikan pola pemakaian tim, misalnya jenis file apa yang paling sering diakses, biar ke depannya lebih mudah nentuin konfigurasi yang pas
Konfigurasi Lanjutan Lewat File headroom.yaml
Buat teman-teman yang udah nyaman sama mode dasar dan mau kontrol lebih detail, Headroom biasanya menyediakan file konfigurasi yang bisa disesuaikan sesuai kebutuhan tim. File ini biasanya diletakkan di root project atau di folder home, tergantung scope yang mau diatur, apakah cuma buat satu project atau berlaku global di semua project yang teman-teman kerjakan.
Contoh struktur konfigurasi yang lazim dipakai kira-kira begini:
# headroom.yaml
version: 1
compression:
default_level: balanced # opsi lain biasanya: light, balanced, aggressive
preserve_recent_turns: 5 # jumlah giliran percakapan terbaru yang tidak dipadatkan
routers:
json:
enabled: true
keep_first_n: 3
keep_last_n: 3
anomaly_detection: true
code:
enabled: true
mode: signature_only # signature_only atau full_body
search_context_lines: 4
logs:
enabled: true
keep_error_levels:
- FATAL
- ERROR
- WARN
prose:
enabled: true
model: local-small
cache_alignment:
enabled: true
strip_dynamic_fields:
- timestamp
- session_id
- request_id
retrieval:
enabled: true
ttl_hours: 24
Beberapa bagian yang paling sering diubah oleh pengguna yang udah paham workflow-nya:
preserve_recent_turns ini penting banget kalau pekerjaan teman-teman butuh konteks percakapan yang runtut, misalnya waktu debugging bareng agent, di mana beberapa giliran terakhir sering saling nyambung. Kalau nilainya diset kelewat kecil, agent bisa "lupa" konteks obrolan yang baru saja terjadi karena keburu dipadatkan.
keep_error_levels di bagian logs berguna buat memastikan level log tertentu nggak pernah ikut kepotong, apapun yang terjadi. Ini cocok kalau teman-teman kerja di lingkungan produksi yang butuh jejak audit lengkap buat level kesalahan kritikal.
strip_dynamic_fields di bagian cache_alignment ini kunci penting buat bikin prompt caching di sisi provider tetap "kena". Kalau ada field yang isinya selalu berubah tiap request, kayak timestamp atau session ID, field itu perlu dipisahkan dari bagian prompt yang stabil, biar bagian awal prompt tetap identik dan cache-nya nggak batal terus-terusan.
ttl_hours di bagian retrieval nentuin berapa lama data asli yang dipadatkan bakal disimpan sebelum akhirnya dibersihkan dari cache lokal. Kalau teman-teman sering butuh balik lagi ke data lama, angka ini bisa dinaikkan, tapi konsekuensinya penyimpanan lokal jadi lebih penuh.
Cara Menguji Konfigurasi Sebelum Dipakai Serius
Salah satu kebiasaan baik yang sering direkomendasikan komunitas adalah nggak langsung pakai konfigurasi baru buat pekerjaan penting. Ada perintah semacam mode dry-run yang biasanya tersedia:
headroom validate --config headroom.yaml
headroom simulate --input contoh_log.txt --config headroom.yaml
Perintah validate bakal ngecek apakah struktur file konfigurasi teman-teman valid, sementara simulate bakal nunjukin gambaran hasil kompresi dari data contoh tanpa benar-benar mengirim apa pun ke LLM. Ini cara paling aman buat ngetes sebelum konfigurasi itu dipakai di pekerjaan yang sesungguhnya.
Headroom vs LiteLLM vs Vercel AI SDK, Mana yang Paling Cocok?
Karena beberapa nama ini sering disebut bareng-bareng waktu ngobrolin soal optimasi context window, ada baiknya diperjelas posisi masing-masing supaya teman-teman nggak salah paham dan mengira ketiganya saling menggantikan.
Aspek | Headroom | LiteLLM | Vercel AI SDK |
Fokus utama | Kompresi dan pemadatan context sebelum dikirim ke model | Lapisan unifikasi API buat banyak penyedia LLM sekaligus | Framework buat membangun aplikasi AI di sisi frontend/backend |
Mengurangi token? | Ya, jadi tujuan utamanya | Tidak secara langsung, kecuali dikombinasikan dengan tool lain | Tidak secara langsung, kecuali dikombinasikan dengan tool lain |
Bisa dipakai bersamaan? | Bisa, biasanya sebagai layer tambahan | Bisa, sering dipasang di tengah sebagai router provider | Bisa, sebagai lapisan di sisi aplikasi |
Cocok buat siapa | Pengguna yang butuh sesi panjang dan hemat biaya token | Tim yang mengelola banyak provider LLM sekaligus | Developer yang membangun produk AI berbasis web |
Dari tabel di atas, kelihatan jelas kalau ketiganya sebenarnya main di lapisan yang berbeda, jadi bukan soal "pilih salah satu", tapi lebih ke gimana caranya mengombinasikan sesuai kebutuhan arsitektur teman-teman. Kalau aplikasi teman-teman dibangun pakai Vercel AI SDK di frontend, terus di backend pakai LiteLLM buat merutekan permintaan ke beberapa provider, Headroom masih bisa masuk sebagai layer tambahan tepat sebelum data itu benar-benar dikirim ke LLM manapun yang dipilih LiteLLM.
Yang perlu diwaspadai justru soal urutan pemasangannya. Kalau Headroom dipasang setelah LiteLLM merutekan ke provider tertentu, pastikan format request yang diterima Headroom masih sesuai dengan yang diharapkan, soalnya beberapa provider punya struktur payload yang sedikit berbeda. Selalu cek dokumentasi integrasi resminya, jangan asal tebak urutan pemasangan cuma berdasarkan intuisi.
Integrasi dengan LangChain: Contoh Kode yang Lebih Lengkap
Kalau di bagian sebelumnya cuma kasih gambaran singkat soal integrasi, sekarang mughu mau kasih contoh yang lebih detail biar teman-teman yang pakai LangChain buat membangun agent bisa langsung nyontek strukturnya.
from headroom.integrations.langchain import HeadroomCallbackHandler
from langchain.agents import AgentExecutor, create_react_agent
from langchain_anthropic import ChatAnthropic
from langchain.tools import Tool
# Siapkan handler kompresi sebagai callback
headroom_handler = HeadroomCallbackHandler(
compression_level="balanced",
preserve_recent_turns=5,
)
llm = ChatAnthropic(model="claude-opus-4")
def baca_log_server(path: str) -> str:
with open(path, "r") as f:
return f.read()
tools = [
Tool(
name="baca_log",
func=baca_log_server,
description="Membaca isi file log server dari path yang diberikan",
)
]
agent = create_react_agent(llm, tools, prompt=None)
executor = AgentExecutor(
agent=agent,
tools=tools,
callbacks=[headroom_handler],
verbose=True,
)
hasil = executor.invoke({"input": "Cari baris FATAL di log/server.log"})
print(hasil["output"])
# Cek statistik penghematan setelah eksekusi
print("Ringkasan kompresi:", headroom_handler.get_stats())
Poin penting dari contoh di atas, kompresi terjadi secara otomatis lewat mekanisme callback, jadi teman-teman nggak perlu manual manggil fungsi compress di setiap titik. Callback ini bakal "mengintip" setiap kali ada output tool yang mau dikirim balik ke LLM, terus memadatkannya di belakang layar sebelum benar-benar masuk ke prompt berikutnya.
Kalau teman-teman penasaran, get_stats() biasanya ngembaliin data semacam ini:
{
"total_tokens_before": 18420,
"total_tokens_after": 3105,
"savings_percent": 83.1,
"cache_hit_rate": 0.76
}
Angka cache_hit_rate ini penting buat dicermati, soalnya kalau angkanya rendah, artinya CacheAligner belum berhasil menstabilkan bagian awal prompt dengan baik, dan itu tandanya masih ada ruang buat optimasi lebih lanjut, misalnya dengan mengecek lagi field dinamis apa yang belum dipisahkan dari bagian stabil prompt.
Kesalahan yang Sering Terjadi Waktu Integrasi dengan Framework
Beberapa hal yang bikin integrasi gagal atau nggak maksimal, berdasarkan pola yang sering dilaporkan pengguna:
-
Lupa menaruh callback handler di parameter
callbackswaktu inisialisasi executor, jadinya kompresi nggak pernah kepanggil sama sekali -
Memasang dua layer kompresi berbeda secara bersamaan tanpa disadari, misalnya udah pakai fitur ringkas otomatis dari LangChain sendiri, ditambah Headroom di atasnya, yang bisa bikin hasil jadi kelewat dipadatkan sampai kehilangan detail
-
Nggak mengatur
preserve_recent_turnssesuai kebutuhan, sehingga agent kelihatan "amnesia" di tengah percakapan panjang -
Menjalankan versi library yang nggak sinkron antara paket utama dan paket integrasinya, yang biasanya bikin error semacam "unexpected keyword argument" waktu inisialisasi
Soal Keamanan Data yang Perlu Diperhatikan
Karena Headroom berjalan sebagai proses lokal, banyak yang beranggapan otomatis aman seratus persen. Anggapan ini nggak seluruhnya salah, tapi juga nggak seluruhnya benar. Ada beberapa hal yang tetap perlu jadi perhatian.
Pertama, meskipun proses kompresinya jalan lokal, data yang udah dipadatkan tetap dikirim ke penyedia LLM pihak ketiga seperti Anthropic atau OpenAI. Artinya, Headroom itu mengurangi jumlah data yang terekspos, bukan menghilangkan eksposur data ke pihak ketiga sepenuhnya. Kalau kebutuhan teman-teman memang harus data nggak pernah keluar dari infrastruktur internal sama sekali, solusi yang lebih tepat adalah pakai model yang dihosting sendiri (self-hosted), bukan sekadar layer kompresi di depan API pihak ketiga.
Kedua, cache lokal yang menyimpan data asli buat keperluan retrieval itu juga perlu diperhatikan lokasinya. Kalau komputer atau server yang menjalankan Headroom dipakai bersama oleh banyak orang, pastikan folder cache-nya punya izin akses yang ketat, soalnya isinya bisa jadi data sensitif yang tadinya sengaja dipadatkan biar nggak keluar utuh ke model, tapi tetap tersimpan utuh di disk lokal.
Ketiga, buat tim yang bekerja di industri dengan regulasi ketat soal data, kayak kesehatan atau keuangan, ada baiknya cek dulu apakah tool kompresi yang dipakai sudah melalui proses audit keamanan, atau minimal punya dokumentasi jelas soal bagaimana data diproses dan disimpan. Jangan cuma mengandalkan klaim "berjalan lokal jadi aman" tanpa verifikasi lebih lanjut, soalnya istilah itu bisa punya makna teknis yang berbeda-beda tergantung implementasinya.
Keempat, kalau tim teman-teman memang mewajibkan kepatuhan tertentu, cek juga apakah komponen kompresi teks yang berbasis model kecil itu memerlukan koneksi keluar (outbound) ke server pihak ketiga cuma buat mengunduh model, atau benar-benar berjalan offline setelah proses unduh pertama. Ini detail kecil yang sering terlewat tapi bisa jadi masalah besar kalau kebijakan keamanan tim teman-teman melarang koneksi keluar yang nggak terdaftar.
Pertanyaan yang Sering Muncul Soal Headroom
Berdasarkan diskusi yang sering beredar di forum dan komunitas developer, berikut beberapa pertanyaan yang paling sering muncul, lengkap sama jawabannya.
Apakah Headroom bikin jawaban AI jadi kurang akurat?
Secara teori, kompresi apapun punya risiko kehilangan detail. Tapi karena Headroom dirancang dengan pendekatan reversible dan pemilihan konten yang dipertahankan (seperti anomali, item pertama dan terakhir, level error kritikal), risiko kehilangan detail penting jadi lebih kecil dibanding truncation asal potong. Meski begitu, tetap disarankan buat menguji sendiri di workload teman-teman, terutama buat data yang punya struktur unik seperti YAML bertingkat atau format kustom lainnya.
Apakah harus ganti semua kode kalau mau pakai Headroom?
Nggak harus. Kalau teman-teman cuma mau solusi cepat, mode wrap atau mode proxy nggak butuh perubahan kode sama sekali. Perubahan kode cuma dibutuhkan kalau teman-teman mau pakai mode library buat kontrol yang lebih detail, misalnya buat memadatkan bagian tertentu dari prompt secara spesifik.
Berapa biaya buat pakai Headroom?
Kalau merujuk ke model open source yang biasa dipakai komunitas, biasanya nggak ada biaya lisensi tambahan buat pemakaian dasar, karena teman-teman cuma bayar biaya token ke penyedia LLM seperti biasa, ditambah resource komputasi lokal buat menjalankan proses kompresinya. Tapi selalu cek ulang halaman resmi tool yang teman-teman pakai, soalnya model bisnis open source kadang berubah, ada yang menambahkan fitur berbayar buat kebutuhan skala enterprise.
Apakah Headroom bisa dipakai bareng ChatGPT atau cuma Claude?
Berdasarkan penjelasan arsitekturnya, Headroom diklaim bisa dipakai buat berbagai penyedia LLM, termasuk OpenAI dan Bedrock, nggak cuma Anthropic. Tapi tingkat kematangan dukungan tiap provider bisa berbeda, jadi tetap cek dokumentasi resmi buat provider spesifik yang teman-teman pakai sebelum benar-benar mengandalkannya di pekerjaan produksi.
Apakah data yang dipadatkan bisa hilang permanen?
Tergantung konfigurasi ttl_hours yang disebutkan di bagian konfigurasi sebelumnya. Kalau waktu penyimpanannya udah lewat, data asli di cache lokal bisa dibersihkan otomatis. Jadi kalau teman-teman butuh data asli buat keperluan audit jangka panjang, jangan cuma mengandalkan cache Headroom, tetap simpan log aslinya di tempat lain yang lebih permanen.
Apakah cocok dipakai buat proyek personal kecil-kecilan?
Kalau proyek personal teman-teman jarang banget kena limit context window, mungkin belum terlalu butuh. Tapi kalau udah mulai sering ngerasa sesi kerja kepotong di tengah jalan gara-gara auto-compact, atau tagihan bulanan mulai kelihatan nggak wajar buat skala pemakaian personal, nggak ada salahnya nyoba, apalagi kalau instalasinya gratis dan nggak butuh komitmen besar.
Kenapa hasil penghematan token mughu beda jauh sama yang dilaporkan orang lain?
Ini pertanyaan yang wajar banget muncul. Penghematan token itu sangat bergantung sama karakteristik data yang teman-teman proses. Kalau workload teman-teman didominasi data yang repetitif kayak log atau hasil pencarian kode, penghematannya biasanya lebih besar. Sebaliknya, kalau kerjaan teman-teman lebih ke eksplorasi hal-hal baru yang belum ada pola berulang, penghematannya wajar lebih kecil. Jangan langsung menyimpulkan tool-nya nggak berfungsi cuma karena angkanya beda dari testimoni orang lain.
Checklist Sebelum Mengadopsi Headroom ke Tim atau Perusahaan
Buat teman-teman yang mau membawa tool semacam ini ke level tim, bukan cuma pemakaian personal, ada baiknya lewatin checklist berikut dulu sebelum benar-benar dijadikan bagian dari workflow resmi.
-
Sudah menguji di workload nyata tim selama minimal beberapa hari, bukan cuma testing sekali di data contoh
-
Sudah membandingkan tagihan LLM sebelum dan sesudah pemasangan, bukan cuma mengandalkan angka
tokens_saveddari statistik internal tool -
Sudah memverifikasi sumber resmi paket yang diinstal, termasuk mengecek publisher di PyPI atau npm, biar nggak salah instal paket serupa yang namanya mirip-mirip
-
Sudah mendiskusikan kebijakan keamanan data dengan tim, terutama soal lokasi penyimpanan cache lokal dan siapa saja yang punya akses ke server yang menjalankan proses ini
-
Sudah menentukan level kompresi default yang aman buat jenis data paling sensitif di tim, baru menaikkan agresivitas secara bertahap
-
Sudah menyiapkan dokumentasi internal singkat soal cara pakai, biar anggota tim baru nggak bingung waktu onboarding
-
Sudah memastikan kompatibilitas dengan fitur cache bawaan provider yang mungkin sudah dipakai tim sebelumnya, biar nggak malah saling mengganggu
-
Sudah punya rencana cadangan kalau suatu saat tool ini berhenti dikembangkan atau berubah arah, misalnya dengan tetap menyimpan log mentah di tempat lain
Checklist semacam ini kelihatannya sepele, tapi berdasarkan pengalaman banyak tim yang buru-buru adopsi tool baru tanpa validasi matang, biasanya justru masalah operasional yang muncul belakangan yang paling bikin repot, bukan masalah teknis di awal pemasangan.
Tips Memaksimalkan Penghematan Token Tanpa Mengorbankan Akurasi
Setelah ngobrolin banyak hal teknis, mughu mau kasih beberapa tips praktis yang bisa langsung dicoba biar hasil kompresi teman-teman lebih optimal, tapi tetap aman buat kualitas jawaban.
Kelompokkan jenis pekerjaan berdasarkan sensitivitas terhadap detail. Kalau pekerjaan itu butuh presisi tinggi, misalnya nge-debug bug yang rumit di kode produksi, mending pakai level kompresi yang lebih ringan biar detail penting nggak kepotong. Sebaliknya, buat eksplorasi awal atau baca-baca dokumentasi umum, level kompresi agresif biasanya aman-aman saja.
Manfaatkan fitur retrieval secara aktif, jangan cuma jadi jaring pengaman pasif. Beberapa pengguna berpengalaman malah sengaja memicu retrieval di awal sesi kerja buat kasus-kasus yang menurut mereka krusial, biar ada jejak jelas kapan data asli benar-benar dibutuhkan lagi.
Perhatikan konsistensi struktur prompt dari waktu ke waktu. Kalau teman-teman sering mengubah-ubah instruksi sistem atau menambahkan metadata dinamis di bagian awal prompt, itu bisa mengganggu kerja CacheAligner. Usahakan bagian yang benar-benar statis, seperti instruksi dasar dan aturan kerja agent, ditaruh di posisi paling awal dan dibiarkan konsisten selama mungkin.
Uji beda level kompresi di jenis data yang sama, bukan cuma sekali coba langsung pakai default. Beberapa tim menemukan bahwa level balanced sudah cukup buat kebutuhan sehari-hari, tapi ada juga kasus di mana level aggressive justru nggak menunjukkan penurunan kualitas berarti buat jenis data tertentu, misalnya log server yang sangat repetitif.
Jangan lupa update tool secara berkala. Karena ini kategori tool yang masih berkembang cepat, kompresor buat jenis data tertentu bisa terus diperbaiki dari waktu ke waktu. Versi lama mungkin belum punya penanganan yang baik buat format data yang teman-teman pakai, sementara versi terbaru sudah mengatasi masalah itu.
Kombinasikan dengan kebiasaan kerja yang rapi. Sebagus apapun tool kompresinya, kalau kebiasaan kerja teman-teman masih asal nyuruh agent baca seluruh folder tanpa filter yang jelas, potensi pemborosan token tetap ada. Kompresi itu membantu mengurangi dampak dari kebiasaan kurang efisien, tapi bukan pengganti buat kebiasaan kerja yang memang sudah terarah dari awal, misalnya dengan menentukan file mana saja yang relevan sebelum meminta agent membacanya.
Dengan menggabungkan pemahaman soal cara kerja di balik layar, konfigurasi yang disesuaikan kebutuhan, dan kebiasaan kerja yang rapi, penghematan token yang teman-teman dapatkan biasanya jauh lebih stabil dibanding cuma mengandalkan setelan bawaan tanpa penyesuaian apapun.
Menyusun Playbook Kompresi Sesuai Jenis Proyek
Satu hal yang sering luput dibahas waktu ngobrolin Headroom adalah soal bagaimana caranya bikin aturan kompresi yang konsisten dipakai lintas proyek, bukan cuma diatur asal-asalan di satu repo terus dilupakan di repo lain. Kalau teman-teman kerja di perusahaan yang punya belasan atau bahkan puluhan repository aktif, bikin satu "playbook" kompresi yang bisa dipakai berulang jelas lebih masuk akal dibanding konfigurasi ulang dari nol setiap kali buka proyek baru.
Playbook ini biasanya nggak perlu rumit-rumit. Cukup catat pola-pola yang paling sering ditemui di tim, misalnya proyek berbasis microservices biasanya punya banyak file konfigurasi YAML dan JSON yang perlu perlakuan khusus, sementara proyek monolith lama biasanya lebih banyak berurusan sama log yang gendut dan hasil pencarian kode yang bertele-tele. Dari situ, teman-teman bisa bikin beberapa template headroom.yaml yang sudah disesuaikan per kategori proyek, tinggal disalin dan sedikit disesuaikan tiap kali mulai kerjaan baru.
Contoh sederhana pembagian kategori yang biasa dipakai:
-
Proyek microservices dengan banyak file konfigurasi: level kompresi
balanced, tapi router JSON diset lebih hati-hati dengankeep_first_ndankeep_last_nyang agak besar biar struktur bertingkat nggak ikut kepotong -
Proyek monolith dengan log produksi besar: fokus di router logs, pastikan semua level
FATAL,ERROR, danWARNselalu dipertahankan, sementara levelINFOatauDEBUGboleh dipadatkan lebih agresif -
Proyek eksplorasi atau riset awal: level kompresi lebih ringan dulu, soalnya di fase ini biasanya belum ada pola berulang yang bisa dipangkas signifikan, jadi kompresi agresif malah berisiko menghilangkan detail yang justru masih dibutuhkan buat memahami codebase
Dengan playbook semacam ini, anggota tim baru juga jadi lebih cepat paham kenapa satu proyek dikonfigurasi berbeda dari proyek lain, bukan cuma ikut-ikutan setelan default tanpa tahu alasannya.
Memantau Dampak Jangka Panjang, Bukan Cuma Sekali Ukur
Banyak tim yang berhenti mengukur setelah minggu pertama pemakaian, padahal karakteristik kerjaan bisa berubah dari waktu ke waktu. Misalnya, di bulan pertama tim mughu sempat menangani banyak kerjaan refactor yang repetitif, jadi angka penghematan tokennya kelihatan besar banget. Tapi begitu masuk fase membangun fitur baru dari nol di bulan berikutnya, angka penghematannya otomatis turun, dan kalau nggak dipantau terus, ini bisa disalahartikan sebagai tool yang "makin nggak efektif", padahal sebenarnya cuma soal karakteristik kerjaan yang berubah.
Solusi paling praktis, jadikan pengecekan headroom stats sebagai kebiasaan rutin, bukan cuma sekali di awal. Beberapa tim bahkan menyambungkan output statistik ini ke dashboard internal mereka, biar bisa dilihat trennya dari waktu ke waktu, mirip kayak memantau metrik lain semacam waktu build atau jumlah bug yang masuk. Dengan begitu, kalau ada penurunan performa kompresi yang signifikan, tim bisa cepat curiga apakah ada perubahan pola kerja, perubahan versi tool, atau memang ada bug baru di kompresornya.
Satu hal lagi yang perlu dicatat, jangan cuma memantau angka penghematan token, tapi juga pantau kualitas jawaban yang dihasilkan agent. Kalau perlu, bikin semacam sample kecil dari pertanyaan-pertanyaan yang sering diajukan ke agent, terus jalankan secara berkala dengan dan tanpa kompresi aktif, lalu bandingkan hasilnya. Cara ini memang butuh sedikit usaha ekstra, tapi jauh lebih meyakinkan dibanding cuma percaya pada asumsi bahwa "kompresi reversible pasti aman".
Kapan Waktu yang Tepat Buat Mengevaluasi Ulang Konfigurasi
Konfigurasi yang cocok di awal pemakaian belum tentu tetap cocok selamanya. Ada beberapa momen yang biasanya jadi sinyal buat teman-teman mengevaluasi ulang setelan kompresi yang sedang dipakai.
Pertama, waktu tim menambah jenis pekerjaan baru yang belum pernah ditangani sebelumnya, misalnya mulai mengerjakan proyek yang banyak berurusan sama data biner atau format file yang nggak umum. Router yang sudah ada mungkin belum punya penanganan khusus buat format semacam itu, jadi ada risiko kompresi jadi kurang optimal atau malah bikin data penting kepotong.
Kedua, setiap kali ada update besar dari tool-nya sendiri. Karena kompresor berbasis model kecil biasanya terus diperbaiki, versi baru bisa punya perilaku yang agak berbeda dari versi sebelumnya. Baca dulu catatan rilisnya sebelum langsung update di environment produksi, siapa tahu ada perubahan default yang memengaruhi hasil kompresi yang sudah teman-teman andalkan selama ini.
Ketiga, waktu ada perubahan besar di sisi harga model dari penyedia LLM. Kalau harga per token turun signifikan, penghematan yang tadinya kelihatan besar secara persentase bisa jadi nggak terlalu berdampak lagi secara nominal, dan mungkin nggak sepadan lagi dengan resource lokal yang harus dikeluarkan buat menjalankan proses kompresinya. Sebaliknya, kalau harga naik, ini justru momen yang pas buat lebih agresif mengoptimalkan konfigurasi biar penghematannya makin maksimal.
Keempat, kalau ada keluhan berulang dari anggota tim soal jawaban agent yang kelihatan aneh atau nggak akurat di jenis data tertentu. Ini sinyal paling jelas buat segera cek ulang router mana yang aktif buat jenis data itu, sekaligus jadi kesempatan buat mendokumentasikan temuan tersebut biar nggak terulang di kemudian hari.
Kesimpulan
Pada akhirnya, urusan kompresi konteks lewat headroom stats ini bukan proyek sekali jadi yang bisa ditinggal begitu saja setelah dikonfigurasi. Angka penghematan token yang bagus di bulan pertama bisa aja perlahan turun bukan karena tool-nya jelek, tapi karena pekerjaan tim memang berubah karakter. Makanya kebiasaan mantau statistik secara rutin, ngecek kualitas jawaban agent, dan sesekali membandingkan hasil dengan-tanpa kompresi itu bukan langkah berlebihan, justru itu yang bikin teman-teman bisa membedakan mana penurunan performa yang wajar dan mana yang butuh investigasi serius.
Empat momen evaluasi ulang yang sudah dibahas, mulai dari munculnya jenis pekerjaan baru, update besar dari tool, perubahan harga model, sampai keluhan berulang dari tim, sebenarnya punya satu benang merah yang sama. Semuanya nunjukkin bahwa konfigurasi kompresi itu sifatnya hidup, harus terus disesuaikan seiring konteks kerja yang berubah, bukan setelan yang cukup diatur sekali di awal terus dilupakan.
Jadi kalau teman-teman sekarang lagi pakai Token Saver atau tool sejenis, jangan cuma puas lihat persentase penghematan yang keren di dashboard. Luangkan waktu buat baca lebih dalam apa yang ada di balik angka itu, dan jadikan pengecekan berkala sebagai bagian dari rutinitas tim, bukan sekadar tugas tambahan. Langkah kecil ini yang bakal nentuin apakah kompresi konteks benar-benar jadi alat bantu yang bisa diandalkan dalam jangka panjang, atau cuma jadi angka bagus yang menipu di permukaan.
Referensi
Headroom Labs. (2026). Headroom: Context Optimization for LLM Agents.
GitHub. (2026). Headroom: Compressing Tool Outputs, Logs, Files, and RAG Chunks Before They Reach the LLM.
Andrew.ooo. (2026). Headroom Review: 60-95% LLM Token Compression.
GitHub. (2026). Headroom Token Saver: Compressing Tool Outputs, Logs, Files, and RAG Chunks for Fewer LLM Tokens.
DEV Community. (2026). Headroom: Cut Your LLM Token Usage by Up to 95% Without Changing Your Answers.
DevShelfHub. (2026). Headroom AI: A Deep Dive into the Context Compression Library.
Medium. (2026). How I Cut Claude Code Token Usage by 90% With Five Tools, Custom Hooks, and Enforcement.
Knightli. (2026). Headroom Guide: Compressing AI Agent Context for Claude Code, Codex, and MCP.
BuildThisNow. (2026). Headroom: Cutting AI Agent Token Costs by Compressing Context.
ExplainX. (2026). Headroom: Context Compression for AI Agents.