Programming
Rahasia Harness Agar Agent Coding AI Bekerja Optimal
Harness agent coding lagi jadi topik yang ramai dibahas di kalangan developer dan tim engineering, terutama sejak coding agent seperti Codex, Claude Code, dan berbagai agent open source mulai dipakai buat kerjaan produksi sungguhan. Kalau teman-teman pernah coba pakai AI coding agent tapi hasilnya kadang ngasal, lupa konteks, atau malah bikin kode yang berantakan, kemungkinan besar masalahnya bukan di model-nya, tapi di harness yang membungkusnya. Artikel ini bakal ngebahas tuntas apa itu agent harness, kenapa soal ini makin krusial, gimana cara bikinnya sendiri, sampai studi kasus nyata dari tim yang sudah membangun produk penuh cuma pakai agent.
Apa Itu Harness Dalam Dunia Agent Coding?

Sebelum lanjut jauh, penting buat menyamakan pemahaman dulu soal istilah ini, karena "harness" sering disalahartikan sebagai sekadar prompt yang panjang.
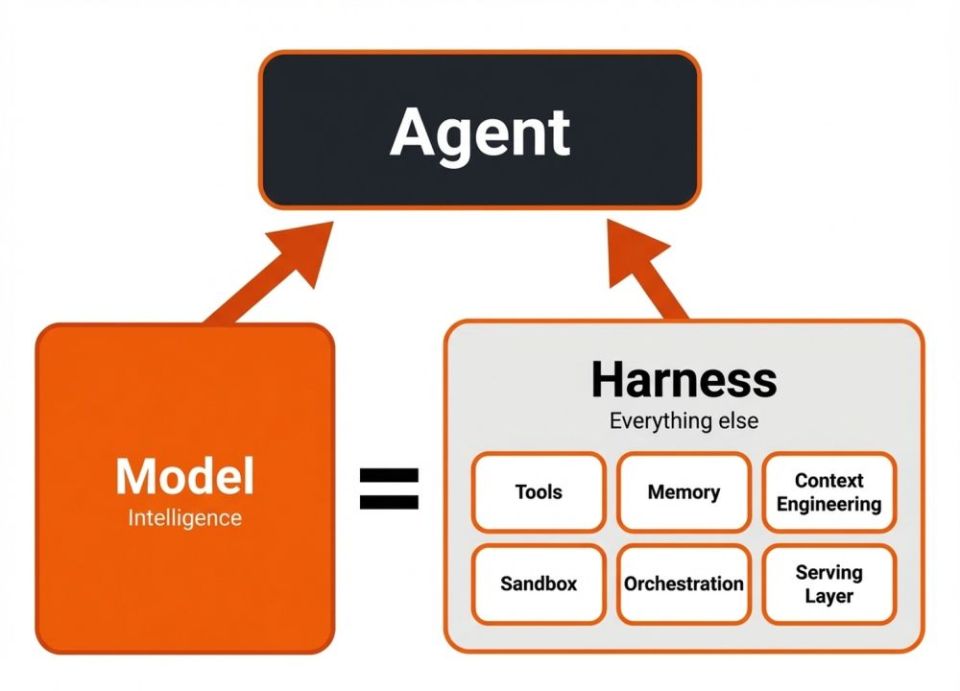
Agent harness adalah lapisan infrastruktur di sekitar large language model yang menyediakan tools, memori, sandbox eksekusi, aturan izin, dan jalur feedback, sehingga model yang tadinya cuma bisa "ngomong" berubah jadi agent yang bisa benar-benar bekerja secara mandiri dalam jangka panjang.
Kalau dianalogikan, model bahasanya itu otaknya, sedangkan harness itu tangan, mata, memori jangka panjang, sekaligus sabuk pengaman buat agent tersebut. Model cuma menyediakan kecerdasan, tapi harness yang menyediakan cara buat kecerdasan itu benar-benar dieksekusi ke dunia nyata, entah itu membaca file, menjalankan perintah shell, atau memvalidasi hasil lewat test.
Beberapa proyek open source bahkan sudah mendefinisikan ini secara eksplisit sebagai infrastruktur lengkap yang membungkus LLM biar jadi agent fungsional, mencakup empat pilar utama: tools untuk bertindak, memori buat menyimpan konteks, sandbox buat eksekusi aman, dan batasan keamanan biar agent nggak "kebablasan".
Kenapa Agent Harness Makin Krusial Sekarang
Mughu pribadi ngerasain langsung pergeseran ini waktu mulai eksperimen pakai coding agent buat kerjaan harian. Awalnya mughu kira, ya tinggal kasih prompt yang detail, beres. Ternyata nggak semudah itu.
Ada riset yang secara spesifik menunjukkan bahwa desain harness punya pengaruh besar terhadap efektivitas agent coding yang berjalan lama, bahkan ketika model dasarnya sama persis. Artinya, dua tim yang pakai model identik bisa dapat hasil yang jauh berbeda cuma karena satu punya harness yang rapi dan satu lagi masih mengandalkan prompt polosan.
Beberapa alasan kenapa harness makin jadi sorotan di 2026:
-
Harness yang optimal itu spesifik per model. Harness yang cocok buat satu model bisa jadi malah bikin performa model lain menurun, dan harus disesuaikan ulang setiap kali model dasarnya berganti.
-
Bottleneck otonomi bukan cuma soal reasoning model, tapi juga soal reliabilitas sistem yang menghubungkan output model ke tindakan nyata dan state yang persisten.
-
Gap antara demo yang keren dan sistem yang jalan stabil di produksi hampir seluruhnya adalah masalah harness engineering, bukan masalah model.
Salah satu contoh paling konkret datang dari tim internal yang membangun produk baru dengan aturan ketat: nol baris kode ditulis manual oleh manusia. Dalam lima bulan, mereka menghasilkan sekitar satu juta baris kode, lewat sekitar 1.500 pull request, dengan tim yang cuma terdiri dari tiga sampai tujuh engineer. Rata-rata throughput-nya mencapai 3,5 pull request per engineer per hari, dan yang menarik, angka ini justru naik ketika tim bertambah orang. Semua itu terjadi bukan karena model tiba-tiba jadi jauh lebih pintar, tapi karena harness di sekitarnya terus dirapikan.
Komponen Inti Sebuah Agent Harness
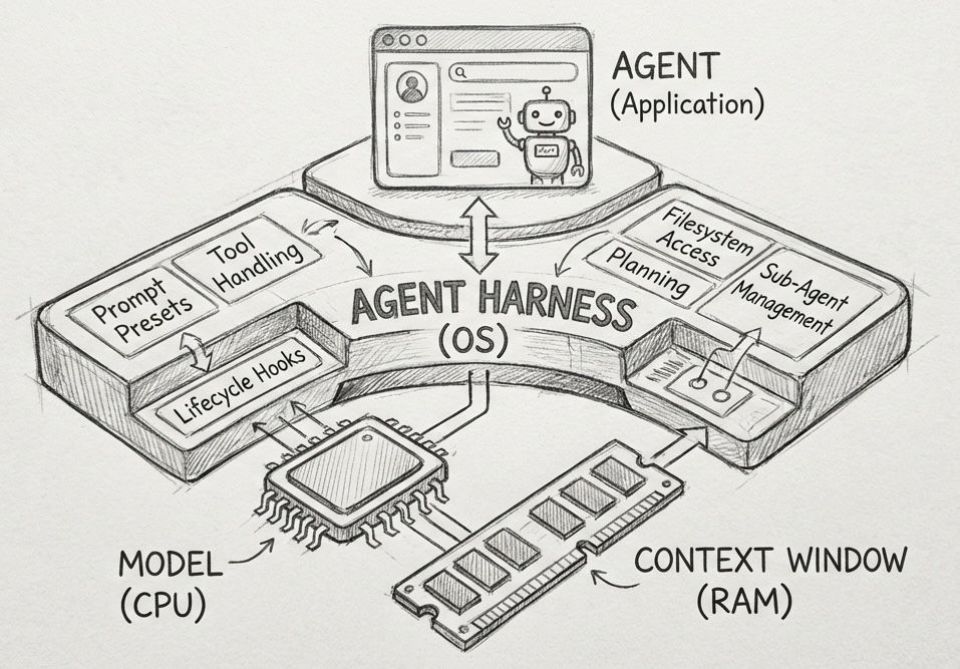
Biar nggak ngambang, mari bedah harness jadi komponen-komponen konkretnya. Kalau teman-teman lagi mau membangun harness sendiri, ini daftar yang wajib dipertimbangkan satu per satu.
-
System prompt. Aturan perilaku tingkat tinggi, gaya kerja, dan batasan umum. Ini lapisan paling ringan tapi paling sering disalahgunakan jadi "tempat sampah" segala instruksi.
-
Tool descriptions dan tool implementations. Definisi tools yang bisa dipanggil agent, mulai dari menjalankan shell, membaca file, sampai memanggil API eksternal. Kualitas deskripsi tool sangat menentukan seberapa sering agent salah pakai tool.
-
Middleware. Lapisan yang menyisip di antara giliran model dan eksekusi tool, bisa dipakai buat memotong output yang kepanjangan, mendeteksi pola loop, atau menyuntikkan peringatan sebelum agent mengambil aksi berisiko.
-
Memori jangka pendek dan jangka panjang. Memori jangka pendek menyimpan konteks sesi yang sedang berjalan, sedangkan memori jangka panjang menyimpan pelajaran yang tetap berguna lintas sesi, seperti pola kesalahan berulang atau strategi yang sudah terbukti jalan.
-
Sandbox eksekusi. Ruang terisolasi tempat agent benar-benar menjalankan perintah, supaya efek sampingnya nggak bocor ke sistem produksi.
-
Verifier atau sensor deterministik. Test, linter, type checker, sampai hasil eksekusi nyata yang jadi patokan objektif apakah pekerjaan agent benar-benar selesai, bukan cuma "kelihatannya" selesai.
Ketujuh komponen ini sebaiknya dibuat lepas satu sama lain alias decoupled. Kalau semuanya ditumpuk jadi satu system prompt raksasa, setiap kali ada masalah baru, teman-teman bakal kesulitan melacak komponen mana yang sebenarnya perlu diperbaiki.
Tutorial: Membangun Harness Sederhana untuk Coding Agent
Bagian ini buat teman-teman yang mau langsung praktik. Mughu akan jalanin lewat contoh harness minimal berbasis Python, konsepnya bisa diadaptasi ke bahasa atau framework apa pun.
Prasyarat
Sebelum mulai, pastikan beberapa hal ini sudah siap:
-
Akses ke API model bahasa (lewat provider apa saja yang mendukung tool calling)
-
Environment eksekusi terisolasi, minimal virtual environment atau container
-
Satu set test atau skrip verifikasi yang jelas untuk tugas yang mau diotomatisasi
-
Pemahaman dasar soal function calling atau tool calling pada LLM
Kenapa prasyarat ini penting? Karena tanpa environment terisolasi, kesalahan agent bisa langsung berdampak ke sistem asli. Dan tanpa skrip verifikasi yang jelas, teman-teman nggak akan tahu apakah harness yang dibangun benar-benar meningkatkan kualitas hasil atau cuma kelihatan lebih rapi di permukaan.
Langkah 1: Definisikan Satu Tool Eksekusi Dasar
def run_shell_command(command: str, timeout_ms: int = 300000) -> dict:
"""Menjalankan perintah shell di sandbox dan mengembalikan output."""
import subprocess
try:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=timeout_ms / 1000,
)
return {"stdout": result.stdout, "stderr": result.stderr, "exit_code": result.returncode}
except subprocess.TimeoutExpired:
return {"error": "timeout", "hint": "Pertimbangkan menjalankan proses di background"}
Kenapa langkah ini penting: tool ini adalah jembatan pertama antara "niat" model dan "aksi" nyata. Tanpa tool eksekusi, agent cuma bisa mengarang teks tanpa pernah benar-benar menyentuh sistem.
Output yang diharapkan setelah tool ini dipanggil dengan perintah sederhana seperti ls:
{"stdout": "main.py\nrequirements.txt\n", "stderr": "", "exit_code": 0}
Langkah 2: Tulis System Prompt yang Fokus pada Kontrak, Bukan Detail Teknis
Kamu menyelesaikan tugas pemrograman secara non-interaktif.
Sebelum menyatakan tugas selesai, selalu jalankan test atau
skrip verifikasi yang sama dengan yang akan dipakai penilai,
bukan pemeriksaan buatanmu sendiri.
Kenapa ini penting: banyak kegagalan agent coding terjadi bukan karena model nggak bisa menulis kode, tapi karena model "menipu diri sendiri" lewat pemeriksaan yang terlalu longgar. Menegaskan aturan "cerminkan evaluator yang sebenarnya" terbukti secara empiris mengurangi kegagalan jenis ini.
Langkah 3: Tambahkan Middleware Peringatan Risiko
Middleware ini memantau riwayat perintah dan memberi peringatan kalau ada pola berisiko, misalnya agent mau menghapus file yang baru saja lolos verifikasi.
class ExecutionRiskMiddleware:
def __init__(self):
self.protected_paths = set()
def after_verification_pass(self, output_paths: list[str]):
self.protected_paths.update(output_paths)
def before_command(self, command: str) -> str | None:
for path in self.protected_paths:
if path in command and any(kw in command for kw in ["rm ", "reset", "truncate"]):
return f"Peringatan: '{path}' sudah terverifikasi. Perintah ini bisa merusak hasil yang valid."
return None
Kenapa langkah ini penting: tanpa penjaga di level eksekusi, agent bisa saja "membersihkan" hasil kerja yang justru sudah benar, cuma karena ingin terlihat rapi. Middleware jenis ini mengubah aturan yang cuma tertulis di prompt menjadi pagar yang benar-benar dipaksakan saat runtime.
Langkah 4: Jalankan dan Verifikasi
Jalankan agent pada beberapa contoh tugas, lalu bandingkan hasilnya dengan skrip verifikasi independen. Jangan percaya laporan "sudah selesai" dari agent begitu saja.
Kesalahan Umum dan Tips Troubleshooting

-
Kesalahan: agent lolos self-check tapi gagal di verifikasi asli. Ini biasanya karena self-check yang dibuat agent cuma memeriksa hal permukaan, seperti jumlah baris atau keberadaan file. Solusinya, paksa agent memakai perintah verifikasi yang sama persis dengan yang dipakai penilai.
-
Kesalahan: proses macet karena timeout default terlalu singkat. Kalau tugasnya melibatkan instalasi paket atau kompilasi berat, sediakan opsi menjalankan proses di background dan mekanisme polling, bukan menunggu di foreground.
-
Kesalahan: agent menghapus hasil yang sudah benar demi "membersihkan" workspace. Tambahkan mekanisme penguncian sederhana seperti pada middleware di Langkah 3.
-
Kesalahan: harness makin besar tapi makin sulit dipelihara. Pisahkan setiap jenis komponen ke file atau modul sendiri-sendiri, jangan digabung dalam satu berkas prompt raksasa.
Review Pendekatan Harness yang Ada Sekarang
Supaya teman-teman punya gambaran lebih luas, berikut ulasan singkat beberapa pendekatan harness yang sedang berkembang.
Harness Manual Buatan Tim Sendiri
Overview: ini adalah pendekatan paling umum, di mana tim menulis sendiri system prompt, tools, dan aturan kerja berdasarkan pengalaman trial and error.
Fitur utama: kontrol penuh atas setiap detail, mudah disesuaikan dengan konvensi tim.
Use case nyata: cocok untuk tim kecil dengan kebutuhan yang cukup spesifik dan berubah-ubah.
Kelebihan:
-
Fleksibel dan mudah dipahami oleh tim internal
-
Tidak butuh infrastruktur tambahan yang rumit
Kekurangan:
-
Sulit diskalakan begitu jumlah komponen bertambah
-
Rawan "membusuk" seiring waktu kalau tidak rutin dirapikan
Cocok untuk: tim yang baru mulai eksplorasi agent coding dan ingin belajar dari nol.
Sebaiknya dilewati oleh: organisasi besar dengan banyak repositori dan kebutuhan konsistensi tinggi lintas tim.
Verdict: titik awal yang bagus, tapi butuh disiplin dokumentasi supaya tidak berantakan dalam jangka panjang.
Harness Berbasis Framework Open Source

Overview: framework seperti ini menyediakan struktur baku untuk tools, middleware, memori, dan sub-agent, sehingga tim tidak perlu membangun semuanya dari nol.
Fitur utama: komponen sudah dipisah rapi per file, mendukung registrasi tools dan middleware lewat konfigurasi.
Use case nyata: riset dan eksperimen yang butuh membongkar-pasang komponen harness dengan cepat.
Kelebihan:
-
Struktur sudah teruji dan terdokumentasi
-
Mempermudah kolaborasi karena format komponennya seragam
Kekurangan:
-
Ada kurva belajar tambahan untuk memahami arsitektur framework
-
Kadang terlalu generik untuk kasus yang sangat spesifik
Cocok untuk: tim engineering yang sudah punya beberapa proyek agent dan ingin standar bersama.
Sebaiknya dilewati oleh: proyek kecil yang hanya butuh satu tool sederhana tanpa kompleksitas tambahan.
Verdict: investasi yang sepadan begitu skala proyek mulai bertambah.
Harness yang Berevolusi Sendiri (Self-Evolving)
Overview: pendekatan ini memakai agent tambahan yang tugasnya khusus menganalisis rekaman eksekusi lalu memperbaiki harness secara otomatis, tanpa campur tangan manusia di setiap iterasi.
Fitur utama: setiap perubahan disertai prediksi dampak yang nantinya diverifikasi di ronde berikutnya, sehingga perubahan yang tidak efektif bisa langsung dibatalkan.
Use case nyata: benchmark jangka panjang seperti penyelesaian tugas terminal kompleks, di mana pola kegagalan berulang tapi sulit dilacak manual.
Kelebihan:
-
Bisa menaikkan tingkat keberhasilan tugas secara bertahap tanpa harus menulis ulang harness manual
-
Hasil evolusinya kadang bisa dipakai ulang di model dasar yang berbeda dengan hasil yang tetap positif
Kekurangan:
-
Kemampuan mendeteksi risiko regresi masih jauh lebih lemah dibanding kemampuan menemukan perbaikan
-
Butuh infrastruktur observability yang cukup matang sebelum bisa dijalankan dengan aman
Cocok untuk: tim riset atau perusahaan dengan volume tugas agent yang tinggi dan sudah punya sistem pencatatan trace yang rapi.
Sebaiknya dilewati oleh: tim yang belum punya dasar observability sama sekali, karena tanpa data trace yang baik, evolusi otomatis ini nggak akan punya bahan bakar.
Verdict: arah yang menjanjikan untuk masa depan harness engineering, tapi masih butuh pengawasan manusia terutama untuk mencegah regresi diam-diam.
Cara Menerapkan Harness Engineering di Tim Kamu
Kalau teman-teman mau mulai menerapkan disiplin harness engineering ini di tim, berikut langkah-langkah yang bisa langsung dipraktikkan.
Step 1: Mulai dari Satu Tool yang Paling Sering Dipakai
Jangan coba membangun semua komponen sekaligus. Pilih satu tool paling krusial, misalnya eksekusi shell atau pembacaan file, lalu rapikan deskripsi dan penanganan errornya lebih dulu.
Step 2: Pisahkan Setiap Jenis Komponen ke Tempatnya Sendiri
Buat struktur folder terpisah untuk system prompt, tool descriptions, middleware, dan memori. Struktur yang rapi ini bakal sangat membantu ketika suatu saat ada bug spesifik yang perlu ditelusuri.
Step 3: Rekam Setiap Trace Eksekusi Agent
Tanpa rekaman trace, teman-teman cuma akan menebak-nebak kenapa agent gagal. Simpan input, tool call, output, dan hasil verifikasi untuk setiap tugas yang dijalankan.
Step 4: Bangun Skrip Verifikasi yang Objektif
Pastikan ada patokan yang jelas dan bisa dieksekusi otomatis untuk menentukan apakah tugas benar-benar selesai, bukan cuma laporan tekstual dari agent.
Step 5: Terapkan Aturan Bertingkat untuk Aksi Berisiko
Bedakan aksi yang aman untuk dilakukan bebas, seperti membaca file, dari aksi yang butuh persetujuan tambahan, seperti menghapus data atau mengubah riwayat repositori.
Step 6: Evaluasi dan Iterasi Berdasarkan Data, Bukan Perasaan
Setiap perubahan pada harness sebaiknya dibandingkan dengan hasil sebelum dan sesudahnya secara terukur, bukan berdasarkan kesan sekilas bahwa "kelihatannya lebih baik".
Tips Tambahan
-
Jangan taruh semua aturan ke dalam satu file instruksi raksasa. Perlakukan dokumen instruksi utama sebagai daftar isi, bukan ensiklopedia.
-
Perlakukan dokumentasi proyek sebagai bagian dari sistem yang harus tetap segar, lengkap dengan mekanisme pengecekan otomatis untuk mendeteksi dokumentasi yang sudah usang.
-
Berikan agent akses ke sinyal observability seperti log dan metrik, bukan cuma kode sumber, supaya agent bisa mendiagnosis masalahnya sendiri.
Studi Kasus: Membangun Produk Tanpa Satu Baris Kode Manual
Background
Sebuah tim kecil di dalam perusahaan teknologi besar memutuskan menjalankan eksperimen ekstrem: membangun produk baru dari repositori kosong, dengan aturan tegas bahwa tidak ada satu baris kode pun yang ditulis manual oleh manusia.
Challenge
Tantangan terbesarnya bukan soal apakah model cukup pintar menulis kode, melainkan bagaimana menyediakan lingkungan kerja yang cukup jelas bagi agent supaya bisa membuat keputusan yang benar tanpa pengawasan langsung manusia di setiap langkah.
Approach
Tim ini mengubah peran mereka dari penulis kode menjadi perancang sistem, konteks, dan jalur feedback. Mereka mendalami pendekatan agent-first di mana manusia berperan sebagai pengarah, sedangkan agent yang mengeksekusi.
Implementation
Beberapa langkah kunci yang mereka lakukan:
-
Membuat dokumen instruksi ringkas sebagai peta navigasi, bukan manual raksasa, lalu menaruh pengetahuan detail di direktori dokumentasi terstruktur yang bisa dijelajahi bertahap
-
Menghubungkan agent dengan alat observability internal, termasuk log dan metrik, supaya agent bisa mendiagnosis masalah performa sendiri
-
Menerapkan arsitektur berlapis yang ketat pada setiap domain bisnis, dipaksakan lewat linter khusus, bukan cuma lewat dokumentasi
-
Menjalankan proses "pembersihan" rutin secara otomatis untuk mengurangi penumpukan pola kode yang kurang rapi
Results
Dalam kurun waktu lima bulan, hasil yang mereka capai cukup mencolok:
Metrik | Hasil |
|---|---|
Jumlah baris kode | Sekitar satu juta baris |
Jumlah pull request | Sekitar 1.500 PR |
Ukuran tim | 3 hingga 7 engineer |
Throughput | Rata-rata 3,5 PR per engineer per hari |
Estimasi waktu dibanding menulis manual | Sekitar sepersepuluh waktu |
Key Learnings
-
Konteks yang terlalu banyak sama buruknya dengan konteks yang terlalu sedikit, karena agent akan mulai mengoptimalkan hal yang salah kalau semuanya dianggap "penting"
-
Batasan arsitektur yang dipaksakan secara mekanis jauh lebih efektif dibanding sekadar dokumentasi yang diharapkan diikuti
-
Throughput justru bisa naik seiring tim bertambah, asal fondasi harness-nya sudah kuat lebih dulu
Perbandingan: Manual Prompting vs Harness Sederhana vs Harness Self-Evolving
Aspek | Manual Prompting | Harness Sederhana | Harness Self-Evolving |
|---|---|---|---|
Kompleksitas awal | Sangat rendah | Sedang | Tinggi |
Konsistensi hasil | Rendah, sangat tergantung prompt tunggal | Sedang hingga tinggi | Tinggi, tapi butuh pengawasan regresi |
Kebutuhan observability | Minim | Sedang | Sangat tinggi |
Skalabilitas ke banyak tugas | Sulit | Cukup baik | Sangat baik |
Risiko regresi diam-diam | Tinggi tapi mudah terlihat | Sedang | Ada, dan justru paling sulit terdeteksi |
Cocok untuk | Eksperimen cepat, tugas satu kali | Tim dengan alur kerja berulang | Organisasi dengan volume tugas besar dan data trace matang |
Rekomendasi berdasarkan kebutuhan:
-
Kalau teman-teman baru mulai eksplorasi, mulai dari manual prompting dulu supaya paham pola kegagalan dasar.
-
Kalau sudah punya alur kerja berulang dengan beberapa tugas serupa, naik ke harness sederhana yang komponennya sudah dipisah rapi.
-
Kalau volume tugasnya besar dan tim sudah punya sistem pencatatan trace yang matang, harness self-evolving bisa jadi langkah lanjutan, asalkan tetap ada pengawasan manusia untuk potensi regresi.
Dampak Bisnis dan Investasi Harness Engineering
Dari sisi keputusan bisnis, harness engineering sebaiknya dilihat sebagai investasi infrastruktur, bukan sekadar eksperimen teknis sesaat. Studi kasus di atas menunjukkan efisiensi waktu pengembangan yang signifikan, dengan estimasi sekitar sepersepuluh dari waktu penulisan manual, sekaligus throughput pull request yang terus meningkat seiring pertumbuhan tim.
Bagi organisasi yang mempertimbangkan investasi ini, beberapa pertimbangan strategis yang relevan:
-
Efisiensi biaya jangka panjang lebih terasa ketika harness sudah distandarkan lintas proyek, karena setiap perbaikan komponen bisa dipakai ulang, bukan dibangun ulang dari nol setiap kali ada proyek baru.
-
Risiko operasional perlu dikelola lewat lapisan izin bertingkat dan gerbang persetujuan manusia untuk aksi yang berdampak luas, seperti perubahan pada infrastruktur produksi.
-
Pengukuran ROI sebaiknya memakai metrik yang objektif, seperti tingkat keberhasilan tugas dan jumlah token yang terpakai per tugas, bukan cuma kesan subjektif dari tim.
Getting Started: Ringkasan untuk Memulai
Bagi teman-teman yang benar-benar baru menyentuh topik ini, berikut ringkasan minimal supaya tidak bingung harus mulai dari mana:
-
Pahami dulu bahwa harness itu infrastruktur di sekitar model, bukan sekadar prompt panjang.
-
Bangun satu tool eksekusi yang jelas dan teruji lebih dulu, jangan langsung ke banyak tools sekaligus.
-
Sediakan skrip verifikasi yang objektif sebelum mempercayai laporan "sudah selesai" dari agent.
-
Rekam setiap trace eksekusi supaya perbaikan harness ke depannya berdasarkan data, bukan tebakan.
Kesalahan yang paling sering terjadi di tahap awal adalah mencoba menyelesaikan semua masalah lewat satu system prompt yang makin lama makin panjang. Begitu prompt sudah ratusan baris, biasanya tanda bahwa sebagian isinya seharusnya dipindah jadi tool, middleware, atau dokumentasi terpisah yang bisa dijelajahi bertahap oleh agent, bukan dijejalkan semua di depan.
Perbandingan Tools dan Framework Harness yang Layak Dilirik
Ngomongin harness tanpa nyebut alat-alat konkret yang bisa dipakai rasanya kurang lengkap. Jadi mari kita lihat beberapa kategori tools yang sering dipakai buat membangun harness, lengkap dengan kelebihan dan kekurangannya masing-masing.
Coding Agent Siap Pakai (Codex, Claude Code, dan Sejenisnya)
Kategori ini adalah agent yang sudah dibungkus harness bawaan dari vendor-nya. Teman-teman nggak perlu bikin harness dari nol, cukup pakai apa yang sudah disediakan.
Kelebihan:
-
Bisa langsung dipakai tanpa setup ribet
-
Harness-nya sudah dioptimalkan khusus buat model yang dipasangkan, jadi kompatibilitasnya lebih terjamin
-
Update dan perbaikan bug ditangani otomatis oleh vendor
Kekurangan:
-
Kontrol atas detail perilaku agent jadi terbatas, teman-teman cuma bisa menyesuaikan lewat konfigurasi yang disediakan
-
Kalau kebutuhan tim sangat spesifik, misalnya integrasi ke sistem internal yang aneh-aneh, sering kali harus nunggu vendor menambahkan dukungan atau nyari jalan memutar sendiri
Mughu pribadi biasanya menyarankan opsi ini buat tim yang belum punya kapasitas engineering khusus buat merawat harness sendiri. Nggak semua tim punya waktu buat bongkar-pasang middleware dan sandbox, dan itu wajar banget.
Framework Harness Open Source
Kategori kedua adalah framework yang menyediakan kerangka kerja buat menyusun tools, memori, dan middleware sendiri, tapi dengan struktur baku yang sudah teruji dari komunitas.
Kelebihan:
-
Bisa disesuaikan sampai level yang sangat detail
-
Komunitasnya biasanya aktif, jadi kalau nemu masalah, kemungkinan besar sudah ada yang pernah mengalami dan membahasnya
-
Nggak terkunci ke satu vendor model tertentu, jadi lebih mudah pindah model kalau ada yang lebih murah atau lebih bagus
Kekurangan:
-
Butuh waktu belajar yang nggak sebentar buat paham arsitekturnya
-
Dokumentasi kadang ketinggalan dibanding kecepatan perubahan kodenya sendiri, jadi teman-teman kadang harus baca langsung kode sumbernya
Kalau tim teman-teman punya minimal satu orang yang nyaman baca kode orang lain dan nggak takut nge-debug masalah yang nggak ada di dokumentasi, opsi ini bisa jadi pilihan yang jauh lebih hemat biaya dalam jangka panjang.
Harness Racikan Sendiri dari Nol
Ini kategori yang paling banyak dibahas di bagian tutorial sebelumnya. Semua komponen, dari tool sampai middleware, dibangun sendiri sesuai kebutuhan spesifik tim.
Kelebihan:
-
Cocok banget kalau kebutuhan bisnisnya sangat khas dan nggak ada framework yang pas
-
Setiap baris kode di harness benar-benar dipahami oleh tim, jadi debugging jadi lebih cepat
Kekurangan:
-
Rawan reinventing the wheel, alias bikin ulang sesuatu yang sebenarnya sudah ada solusinya di luar sana
-
Biaya perawatan jangka panjang lebih tinggi, karena semua tanggung jawab ada di tim internal
Tabel Ringkas Perbandingan
Kategori | Kecepatan Mulai | Fleksibilitas | Biaya Perawatan | Cocok Untuk |
Agent siap pakai | Sangat cepat | Rendah | Rendah | Tim kecil, kebutuhan umum |
Framework open source | Sedang | Tinggi | Sedang | Tim engineering dengan beberapa proyek agent |
Racikan sendiri | Lambat | Sangat tinggi | Tinggi | Kebutuhan bisnis yang sangat khas |
Nggak ada jawaban "paling benar" di sini. Yang ada cuma jawaban yang paling cocok sama kondisi tim teman-teman sekarang. Kalau baru mulai, nggak masalah pakai agent siap pakai dulu, baru pindah ke opsi lain begitu kebutuhannya makin spesifik.
Kesalahan Fatal yang Sering Bikin Harness Gagal Total
Selain kesalahan-kesalahan kecil yang sudah dibahas di bagian troubleshooting sebelumnya, ada beberapa kesalahan yang levelnya lebih fatal, karena bisa bikin seluruh proyek harness gagal bukan cuma di satu tugas, tapi di skala yang lebih luas.
Masalah: Memberi Agent Terlalu Banyak Kekuasaan Sejak Awal
Ini kesalahan yang paling sering mughu lihat di tim yang baru mulai. Karena kepingin cepat lihat hasil, agent langsung dikasih akses penuh ke semua sistem, termasuk yang sifatnya produksi.
Solusi: mulai dari lingkungan yang benar-benar terisolasi dulu. Baru setelah agent terbukti konsisten lolos verifikasi di lingkungan aman, naikkan levelnya secara bertahap. Anggap ini kayak memberi kunci mobil ke anak yang baru belajar nyetir. Nggak langsung dilepas ke jalan tol.
Masalah: Verifikasi yang Terlalu Longgar atau Terlalu Ketat
Dua ekstrem ini sama bahayanya. Kalau verifikasinya terlalu longgar, agent bisa lolos padahal hasilnya sebenarnya nggak layak dipakai. Tapi kalau terlalu ketat, agent malah keteteran menyelesaikan tugas yang sebenarnya sederhana, karena tiap langkah kecil dituntut sempurna.
Solusi: samakan standar verifikasi dengan standar yang dipakai buat menilai pekerjaan manusia di tim yang sama. Kalau standar buat reviewer manusia adalah "lolos test dan nggak ada regresi", jangan bikin standar buat agent jadi lebih ketat atau lebih longgar dari itu tanpa alasan yang jelas.
Masalah: Nggak Ada Rencana Buat Menangani Kegagalan Berulang
Kadang agent bisa terjebak dalam loop, mencoba cara yang sama berulang-ulang padahal sudah jelas nggak berhasil. Tanpa mekanisme deteksi, ini bisa menghabiskan waktu dan biaya token secara signifikan tanpa hasil apa pun.
Solusi: tambahkan penghitung percobaan di level middleware. Kalau sebuah pendekatan sudah gagal lebih dari batas tertentu, paksa agent buat mengubah strategi atau eskalasi ke manusia, bukan terus mencoba dengan cara yang identik.
class RetryLimitMiddleware:
def __init__(self, max_attempts: int = 3):
self.max_attempts = max_attempts
self.attempt_log = {}
def before_command(self, task_id: str, command_signature: str) -> str | None:
key = (task_id, command_signature)
self.attempt_log[key] = self.attempt_log.get(key, 0) + 1
if self.attempt_log[key] > self.max_attempts:
return "Pendekatan ini sudah dicoba berkali-kali dan gagal. Ubah strategi atau eskalasi ke manusia."
return None
Masalah: Mengabaikan Biaya Token Sampai Tagihan Membengkak
Ini masalah yang sering ketahuan telat, biasanya pas laporan biaya bulanan datang. Agent yang boros dalam memanggil tools atau menyimpan konteks yang nggak perlu bisa bikin biaya operasional jauh di luar perkiraan awal.
Solusi: pantau konsumsi token per tugas sejak hari pertama, bukan cuma pantau berhasil atau nggaknya tugas. Tetapkan semacam anggaran token per jenis tugas, dan kasih peringatan kalau ada tugas yang jauh melebihi anggaran itu tanpa alasan yang jelas.
Cara Mengukur Apakah Harness Kamu Beneran Efektif
Banyak tim berhenti di tahap "kelihatannya sudah lebih baik" tanpa pernah benar-benar mengukur secara objektif. Bagian ini bakal ngajak teman-teman menyusun metrik yang lebih konkret.
Metrik Tingkat Keberhasilan Tugas
Metrik paling dasar adalah persentase tugas yang benar-benar lolos verifikasi independen, bukan cuma laporan "selesai" dari agent. Hitung ini secara rutin, misalnya per minggu, biar teman-teman bisa lihat tren naik atau turunnya seiring waktu.
Metrik Efisiensi Token dan Waktu
Selain berhasil atau nggak, penting juga melacak berapa banyak token dan waktu yang dipakai buat menyelesaikan satu jenis tugas. Kalau harness yang baru justru menghabiskan token lebih banyak buat hasil yang sama, itu tanda ada yang perlu dirapikan, walaupun tingkat keberhasilannya kelihatan bagus.
Metrik Jumlah Intervensi Manusia
Metrik ini sering dilupakan padahal penting banget. Hitung berapa kali manusia harus turun tangan buat memperbaiki atau mengarahkan ulang agent dalam satu periode. Harness yang makin matang seharusnya menurunkan angka ini seiring waktu, bukan malah menaikkannya.
Metrik Waktu Pemulihan dari Kesalahan
Ketika agent melakukan kesalahan, seberapa cepat sistem bisa mendeteksi dan memulihkan diri? Harness yang bagus bukan berarti nggak pernah salah sama sekali, tapi lebih ke soal seberapa cepat kesalahan itu ketahuan dan diperbaiki sebelum berdampak lebih luas.
Metrik | Cara Mengukur | Target Umum |
Tingkat keberhasilan tugas | Jumlah tugas lolos verifikasi dibagi total tugas | Naik stabil per iterasi harness |
Efisiensi token | Rata-rata token per jenis tugas | Turun atau stabil meski kompleksitas naik |
Intervensi manusia | Jumlah eskalasi manual per periode | Menurun seiring kematangan harness |
Waktu pemulihan | Rata-rata waktu dari kesalahan terdeteksi sampai diperbaiki | Sependek mungkin, idealnya otomatis |
Rekam semua metrik ini di satu dashboard yang sama, jangan tersebar di banyak tempat. Begitu teman-teman punya data historisnya, keputusan buat mengubah komponen harness jadi jauh lebih mudah dipertanggungjawabkan ke tim atau atasan.
Keamanan dan Tata Kelola dalam Harness
Semakin besar kewenangan yang diberikan ke agent, semakin penting juga lapisan tata kelola yang menjaga supaya kewenangan itu nggak disalahgunakan, baik secara sengaja maupun nggak sengaja.
Prinsip Least Privilege Buat Agent
Prinsip ini sebenarnya bukan hal baru, sudah lama dipakai di dunia keamanan sistem manusia. Intinya sederhana, kasih agent akses paling minim yang dibutuhkan buat menyelesaikan tugasnya, jangan lebih.
Contoh penerapannya:
-
Agent yang tugasnya cuma membaca dan menganalisis log nggak perlu diberi akses tulis ke database produksi
-
Agent yang bertugas menulis kode nggak perlu diberi kewenangan buat mengubah pengaturan izin akses di sistem
-
Kalau ada tugas yang butuh akses lebih luas, buat proses persetujuan tambahan, jangan otomatis diberikan begitu saja
Audit Trail yang Bisa Ditelusuri
Setiap aksi yang diambil agent sebaiknya tercatat dengan jelas, siapa yang memicu, kapan, dan apa hasilnya. Ini bukan cuma buat kebutuhan debugging, tapi juga buat kebutuhan pertanggungjawaban kalau suatu saat ada masalah yang harus ditelusuri ke belakang.
def log_agent_action(agent_id: str, action: str, target: str, result: dict):
entry = {
"timestamp": datetime.utcnow().isoformat(),
"agent_id": agent_id,
"action": action,
"target": target,
"result_summary": result.get("exit_code", "n/a"),
}
append_to_audit_log(entry)
Kenapa ini penting: tanpa audit trail yang rapi, ketika ada insiden, tim cuma bisa menebak-nebak apa yang sebenarnya terjadi. Dengan pencatatan yang konsisten, penyelidikan bisa dilakukan dalam hitungan menit, bukan berjam-jam.
Gerbang Persetujuan Manusia Buat Aksi Berdampak Luas
Nggak semua aksi layak dijalankan otomatis tanpa persetujuan. Aksi yang berdampak luas, misalnya menghapus data pelanggan atau mengubah konfigurasi infrastruktur produksi, sebaiknya tetap butuh konfirmasi manusia, walaupun agent sudah punya rekam jejak yang bagus sebelumnya.
Rancang gerbang persetujuan ini biar nggak jadi hambatan yang bikin frustrasi, tapi juga nggak terlalu longgar sampai kehilangan fungsinya. Salah satu cara yang cukup efektif adalah membagi aksi jadi tiga tingkat.
-
Tingkat hijau: aksi aman, bisa langsung dijalankan tanpa persetujuan, misalnya membaca file atau menjalankan test.
-
Tingkat kuning: aksi yang butuh notifikasi ke manusia tapi nggak perlu menunggu persetujuan aktif, misalnya membuat pull request baru.
-
Tingkat merah: aksi yang wajib menunggu persetujuan eksplisit sebelum dijalankan, misalnya menghapus branch produksi atau mengubah kredensial.
Pertanyaan yang Sering Muncul Soal Agent Harness
Apakah Harness Cuma Relevan Buat Perusahaan Besar?
Nggak juga. Justru tim kecil yang sering paling merasakan manfaatnya, karena harness yang rapi bikin satu atau dua orang bisa menangani volume kerja yang biasanya butuh tim lebih besar. Studi kasus yang sudah dibahas sebelumnya menunjukkan tim cuma tiga sampai tujuh orang bisa menghasilkan output yang setara tim jauh lebih besar, justru karena fondasi harness-nya kuat.
Apakah Harness Bikin Peran Developer Jadi Nggak Relevan?
Ini kekhawatiran yang wajar, tapi kenyataannya peran developer bergeser, bukan hilang. Fokusnya pindah dari menulis setiap baris kode secara manual, ke merancang sistem, menentukan batasan, dan menjaga kualitas lewat verifikasi. Dari studi kasus sebelumnya, tim yang berhasil justru menyebut diri mereka berubah jadi "perancang sistem dan konteks", bukan penulis kode lagi.
Berapa Lama Waktu yang Dibutuhkan Buat Membangun Harness yang Layak Pakai?
Nggak ada angka pasti, karena sangat bergantung pada kompleksitas tugas dan seberapa matang infrastruktur observability yang sudah ada. Tapi dari pengalaman mughu sendiri, versi paling sederhana dari harness, yang cuma punya satu tool eksekusi dan satu skrip verifikasi, bisa dibangun dalam hitungan hari. Yang butuh waktu lama justru proses merapikan dan mengiterasi berdasarkan data, yang memang nggak ada ujungnya kalau dilihat sebagai proses yang terus berjalan.
Apakah Harness yang Bagus Buat Satu Model Otomatis Bagus Buat Model Lain?
Nggak, dan ini poin yang sudah disinggung di bagian awal artikel. Harness yang optimal cenderung spesifik per model. Kalau teman-teman ganti model dasar, jangan berasumsi harness lama bisa dipakai apa adanya. Sisihkan waktu buat evaluasi ulang, minimal di beberapa tugas representatif, sebelum benar-benar pindah sepenuhnya.
Apa Tanda Paling Jelas Kalau Harness Sudah Waktunya Direvisi?
Tanda paling jelas biasanya muncul lewat pola kegagalan yang berulang di jenis tugas yang sama. Kalau agent terus-menerus salah di titik yang serupa, itu bukan salah agent-nya, tapi tanda ada komponen harness yang perlu diperbaiki, entah itu tool description yang ambigu, system prompt yang membingungkan, atau verifikasi yang nggak mencerminkan standar sebenarnya.
Apakah Harness Self-Evolving Aman Dipakai di Produksi Sekarang?
Untuk sebagian besar tim, jawabannya masih perlu kehati-hatian. Seperti yang sudah dibahas di bagian review, kemampuan self-evolving harness buat mendeteksi regresi masih jauh lebih lemah dibanding kemampuannya menemukan perbaikan baru. Kalau mau coba, sebaiknya jalankan dulu di lingkungan staging dengan pengawasan manusia yang aktif, sebelum dipercayakan sepenuhnya ke produksi.
Tren Harness Engineering yang Perlu Dipantau
Standardisasi Format Tool Description
Makin banyak tim yang mulai menyadari kalau kualitas deskripsi tool punya pengaruh besar terhadap akurasi agent. Ke depannya, kemungkinan bakal muncul lebih banyak standar atau konvensi bersama soal cara menulis deskripsi tool yang efektif, mirip seperti dokumentasi API yang punya standar penulisan tersendiri.
Observability Sebagai Kebutuhan Dasar, Bukan Tambahan
Dulu observability sering dianggap "nice to have", sesuatu yang bisa ditambahkan belakangan kalau ada waktu. Sekarang, terutama buat tim yang serius membangun agent otonom, observability mulai dianggap kebutuhan dasar sejak hari pertama, karena tanpa itu, hampir mustahil melakukan perbaikan harness berbasis data.
Munculnya Peran Baru: Harness Engineer
Beberapa organisasi mulai memisahkan peran ini secara eksplisit dari peran software engineer biasa. Harness engineer fokus penuh pada infrastruktur di sekitar agent, mulai dari tool, middleware, sampai sistem verifikasi, sementara software engineer lain tetap fokus pada logika bisnis inti.
Kolaborasi Antar Agent yang Makin Matang
Selain harness buat satu agent, mulai berkembang juga pola di mana beberapa agent bekerja sama dalam satu tugas besar, masing-masing dengan peran spesifik, misalnya satu agent fokus menulis kode, satu lagi fokus review, dan satu lagi fokus menjalankan test. Pola kolaborasi semacam ini menuntut harness yang bisa mengatur komunikasi antar agent, bukan cuma komunikasi antara satu agent dengan manusianya.
Checklist Praktis Sebelum Deploy Agent Harness ke Produksi
Sebelum benar-benar melepas harness buat menangani tugas produksi tanpa pengawasan ketat, ada baiknya teman-teman cek daftar ini dulu.
-
Semua tool punya deskripsi yang jelas dan sudah diuji dengan beberapa skenario penggunaan yang berbeda
-
Skrip verifikasi mencerminkan standar penilaian yang sama dengan yang dipakai buat menilai pekerjaan manusia
-
Ada mekanisme deteksi loop atau percobaan berulang yang gagal
-
Aksi berisiko tinggi sudah dikategorikan dan butuh persetujuan manusia sebelum dijalankan
-
Audit trail berjalan dan bisa ditelusuri kapan saja dibutuhkan
-
Metrik tingkat keberhasilan, efisiensi token, dan jumlah intervensi manusia sudah terpantau di dashboard
-
Sudah ada rencana rollback kalau harness versi baru justru menurunkan performa dibanding versi sebelumnya
-
Dokumentasi komponen harness tersimpan rapi dan mudah diakses tim lain, bukan cuma di kepala satu orang saja
Checklist ini nggak harus semuanya centang seratus persen sebelum mulai, tapi semakin banyak yang belum tercentang, semakin besar juga risiko yang perlu diwaspadai saat deploy.
Pelajaran yang Mughu Petik Setelah Bergelut dengan Harness
Menutup bagian ini dengan sedikit refleksi personal. Setelah beberapa waktu bereksperimen dengan berbagai bentuk harness, baik yang sederhana maupun yang lebih kompleks, ada beberapa pelajaran yang mughu rasa layak dibagikan.
Pertama, godaan terbesar di awal adalah pengin bikin harness yang "lengkap" dari hari pertama. Padahal, harness yang bagus itu biasanya tumbuh dari yang kecil dan sederhana, bukan dirancang sempurna sejak awal. Mughu sendiri pernah menghabiskan waktu berhari-hari merancang sistem memori jangka panjang yang rumit, padahal masalah sebenarnya ada di deskripsi tool yang ambigu, bukan di soal memori sama sekali.
Kedua, kepercayaan ke agent itu harus dibangun secara bertahap, sama seperti kepercayaan ke rekan kerja baru. Nggak masuk akal memberi akses penuh ke sistem produksi ke orang yang baru masuk hari pertama, dan prinsip yang sama berlaku ke agent. Butuh rekam jejak yang terbukti lewat verifikasi berulang sebelum kewenangannya diperluas.
Ketiga, dan ini mungkin yang paling penting, harness itu bukan proyek yang punya garis akhir. Begitu satu masalah selesai diperbaiki, biasanya muncul masalah baru yang levelnya lebih halus. Bukan berarti ini kerja tanpa ujung yang bikin capek, tapi lebih ke soal mindset. Kalau teman-teman berharap suatu saat harness bakal "beres total" dan nggak perlu dipegang lagi, kemungkinan besar bakal kecewa. Tapi kalau dilihat sebagai proses perbaikan berkelanjutan, hasilnya justru terasa lebih memuaskan, karena setiap iterasi kecil terasa seperti kemajuan nyata, bukan beban yang nggak ada habisnya.
Mengintegrasikan Harness ke Pipeline CI/CD yang Sudah Ada
Kalau tim teman-teman sudah punya pipeline CI/CD yang jalan lama sebelum era agent coding ramai seperti sekarang, pertanyaan yang sering muncul adalah: harness ini ditaruh di mana? Apakah harus menggantikan pipeline yang sudah ada, atau cukup numpang di atasnya?
Dari pengalaman mughu ngobrol sama beberapa tim yang sudah lebih dulu jalan, jawaban paling aman biasanya numpang di atas pipeline yang sudah ada, bukan bongkar total dari awal. Agent cukup diperlakukan seperti kontributor baru yang bikin pull request. Setiap perubahan yang diajukan agent tetap harus lewat proses yang sama dengan kontribusi manusia, mulai dari test otomatis, linter, sampai review sebelum merge. Bedanya cuma di siapa yang menulis kodenya.
Pola yang biasanya jalan dengan baik kira-kira begini:
-
Agent bekerja di branch terpisah, bukan langsung di branch utama
-
Setiap commit dari agent otomatis memicu pipeline CI yang sama persis dengan yang dipakai buat kode manusia
-
Hasil pipeline, termasuk log kegagalan test, dikirim balik ke agent lewat tool yang sudah dibahas di bagian tutorial sebelumnya
-
Merge ke branch utama tetap butuh gerbang persetujuan sesuai tingkat risiko yang sudah dijelaskan di bagian tata kelola
Keuntungan dari pendekatan numpang ini, tim nggak perlu mempertaruhkan infrastruktur yang sudah stabil cuma buat ngejar tren agent coding. Kalau ternyata harness yang dibangun belum matang, tim masih bisa balik ke alur kerja manual tanpa harus membongkar ulang pipeline dari nol. Risikonya jadi lebih terkendali, dan itu penting banget terutama buat tim yang baru mulai eksplorasi topik ini.
Satu hal yang perlu diwaspadai, jangan biarkan agent punya jalan pintas buat melewati pipeline CI demi alasan "biar lebih cepat". Godaan ini sering muncul waktu agent terus-menerus gagal di satu tahap tertentu, dan kelihatan gampang banget cuma tinggal menonaktifkan satu langkah verifikasi. Begitu godaan ini dituruti sekali, biasanya bakal terus terulang, dan pipeline yang tadinya jadi jaring pengaman malah jadi formalitas kosong.
Memilih Model Dasar yang Cocok dengan Harness Kamu
Bagian yang sering dilupakan waktu membicarakan harness adalah soal kecocokan antara harness dan model dasar yang dipakai. Seperti yang sudah disinggung di bagian awal, harness yang optimal itu cenderung spesifik per model, jadi pemilihan model bukan keputusan yang bisa dipisahkan dari desain harness.
Beberapa hal praktis yang bisa jadi patokan waktu memilih model buat dipasangkan dengan harness:
-
Konsistensi dalam memanggil tool. Ada model yang rajin banget memanggil tool sesuai skema yang diminta, ada juga yang sering melenceng dari format yang diharapkan. Kalau harness teman-teman sangat bergantung pada tool calling yang presisi, uji dulu konsistensi ini di beberapa skenario sebelum benar-benar komit.
-
Kemampuan mengikuti instruksi panjang tanpa mulai "lupa" di tengah jalan. Ini penting terutama buat tugas yang butuh banyak langkah berurutan, karena kalau model mulai kehilangan jejak instruksi di tengah proses, hasil kerjanya jadi nggak bisa diandalkan.
-
Biaya per token dibanding kualitas hasil. Model yang lebih mahal belum tentu otomatis lebih hemat secara keseluruhan, karena kalau harness-nya belum pas, model mahal sekalipun bisa tetap butuh banyak percobaan ulang.
Mughu sendiri pernah coba pola yang menurut mughu cukup adil buat membandingkan model, yaitu menjalankan set tugas yang sama lewat harness yang identik, lalu bandingin hasilnya berdasarkan metrik yang sudah dibahas di bagian pengukuran sebelumnya. Bukan cuma lihat tingkat keberhasilan tugasnya, tapi juga efisiensi token dan seberapa sering perlu campur tangan manusia. Dengan cara ini, keputusan pindah model jadi berdasarkan data, bukan cuma ikut tren "model baru pasti lebih bagus".
Kalau suatu saat teman-teman memutuskan pindah model dasar, jangan langsung migrasi penuh dalam satu waktu. Jalankan dulu di sebagian kecil tugas, bandingkan hasilnya dengan model lama lewat harness yang sama, baru perluas kalau hasilnya memang konsisten lebih baik atau minimal setara.
Membangun Budaya Tim yang Cocok Buat Harness Engineering
Harness yang bagus secara teknis nggak akan banyak berguna kalau budaya tim di sekitarnya nggak mendukung. Ada beberapa kebiasaan tim yang mughu perhatikan cukup berpengaruh terhadap keberhasilan harness engineering dalam jangka panjang.
Pertama, review pekerjaan agent sebaiknya diperlakukan dengan standar yang sama seperti review pekerjaan rekan kerja, bukan lebih santai dan bukan juga lebih keras tanpa alasan jelas. Kalau reviewer mulai malas memeriksa pull request cuma karena "ah ini kan buatan agent, pasti udah bener", itu tanda bahaya. Sebaliknya, kalau reviewer jadi terlalu paranoid dan memeriksa setiap baris dengan standar yang jauh lebih ketat dibanding kode manusia, proses kerja malah jadi lebih lambat daripada sebelum ada agent sama sekali.
Kedua, dorong kebiasaan mendokumentasikan setiap perubahan pada komponen harness, sekecil apa pun perubahannya. Kebiasaan ini kelihatan sepele di awal, tapi begitu tim bertambah orang atau ada anggota yang keluar masuk, dokumentasi inilah yang jadi penyelamat waktu ada yang bingung kenapa suatu middleware berperilaku tertentu. Tanpa dokumentasi yang jalan, pengetahuan soal harness cuma nyangkut di kepala satu atau dua orang, dan itu risiko yang cukup besar buat kelangsungan proyek.
Ketiga, biasakan tim buat merayakan perbaikan kecil pada harness, bukan cuma pencapaian besar seperti peluncuran fitur baru. Soalnya, sebagian besar kemajuan di harness engineering memang datang dari perbaikan kecil yang berulang, bukan lompatan besar sekali jadi. Kalau tim cuma menghargai pencapaian besar, motivasi buat merapikan hal-hal kecil seperti deskripsi tool yang ambigu bisa perlahan hilang.
Menyiapkan Onboarding Buat Anggota Tim yang Baru Bergabung
Begitu harness sudah cukup matang, biasanya muncul kebutuhan baru: bagaimana caranya anggota tim yang baru bergabung bisa cepat paham cara kerja sistem ini tanpa harus membaca seluruh riwayat commit dari awal.
Beberapa pendekatan yang cukup membantu buat proses ini:
-
Siapkan satu dokumen ringkas yang menjelaskan filosofi harness secara umum, lengkap dengan alasan di balik keputusan desain utama, bukan cuma daftar konfigurasi teknis
-
Sediakan beberapa contoh trace eksekusi yang bisa dipelajari, baik yang berhasil maupun yang gagal, supaya anggota baru punya gambaran nyata soal cara agent bekerja di lingkungan tim tersebut
-
Ajak anggota baru buat mulai dari tugas kecil yang risikonya rendah, sambil mengamati bagaimana harness merespons di setiap tahap, sebelum dipercaya menangani konfigurasi yang lebih sensitif
Pendekatan ini sebenarnya mirip banget dengan prinsip least privilege yang sudah dibahas buat agent, cuma sekarang diterapkan ke manusia yang baru belajar mengelola harness. Kepercayaan itu memang harus dibangun bertahap, baik buat agent maupun buat orang yang bertanggung jawab mengarahkannya.
Satu tips tambahan yang mughu rasa cukup berguna, minta anggota baru buat mencoba memicu kegagalan secara sengaja di lingkungan aman, bukan cuma belajar dari kasus yang berjalan lancar. Dengan melihat langsung bagaimana middleware seperti RetryLimitMiddleware atau ExecutionRiskMiddleware merespons situasi bermasalah, pemahaman soal cara kerja harness jadi jauh lebih nempel dibanding cuma baca dokumentasi tanpa praktik langsung.
Kesimpulan
Kalau ditarik garis besarnya, mengelola harness agent coding sebenarnya bukan soal mencari satu konfigurasi ajaib yang bisa dipasang sekali lalu dilupakan. Ini lebih ke soal membangun kebiasaan: standar review yang konsisten, dokumentasi yang hidup, dan budaya tim yang menghargai perbaikan kecil sama seriusnya dengan peluncuran fitur besar. Ketiganya saling mengunci satu sama lain. Review yang longgar bikin dokumentasi jadi tidak terpercaya, dan dokumentasi yang mati bikin proses onboarding jadi lambat serta rawan salah paham.
Bagian onboarding yang dibahas di atas sebenarnya cuma cermin dari prinsip yang sama dengan yang berlaku buat agent itu sendiri, yaitu kepercayaan yang dibangun bertahap lewat least privilege. Anggota baru diberi ruang buat mencoba di lingkungan aman, termasuk sengaja memicu kegagalan lewat middleware seperti RetryLimitMiddleware atau ExecutionRiskMiddleware, sebelum akhirnya dipercaya menyentuh bagian yang lebih sensitif. Pendekatan ini terbukti lebih efektif dibanding sekadar menyodorkan dokumen teknis, karena pemahaman yang didapat dari pengalaman langsung jauh lebih menempel.
Pada akhirnya, harness yang baik bukan yang paling rumit atau paling banyak fiturnya, melainkan yang paling mudah dipahami dan dipercaya oleh tim yang menjalankannya sehari-hari. Kalau kamu sedang membangun atau merapikan harness sendiri, mulai saja dari langkah kecil yang paling terasa menyakitkan sekarang, entah itu memperbaiki deskripsi tool yang ambigu atau menuliskan satu dokumen filosofi singkat, lalu jadikan itu kebiasaan tim, bukan sekadar tugas satu orang.
Referensi
Martin Fowler. (2026). Harness engineering for coding agent users.
OpenAI. (2026). Harness engineering: Leveraging Codex in an agent-first world.
GitHub. (2026). Best of agent harnesses and harness techniques.
arXiv. (2026). Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses.
Harness Engineering. (2026). Harness engineering knowledge graph.
GitHub. (2026). OpenHarness: Open agent harness.
Harness Engineering. (2026). The complete guide to agent harness: What it is and why it matters.
Anthropic. (2026). Harness design for long-running application development.
arXiv. (2026). Code as agent harness: Toward executable, verifiable, and stateful agent systems.
Harness. (2026). Worker agents.