Programming
CI/CD Workflow for Pull Requests: A Complete Guide
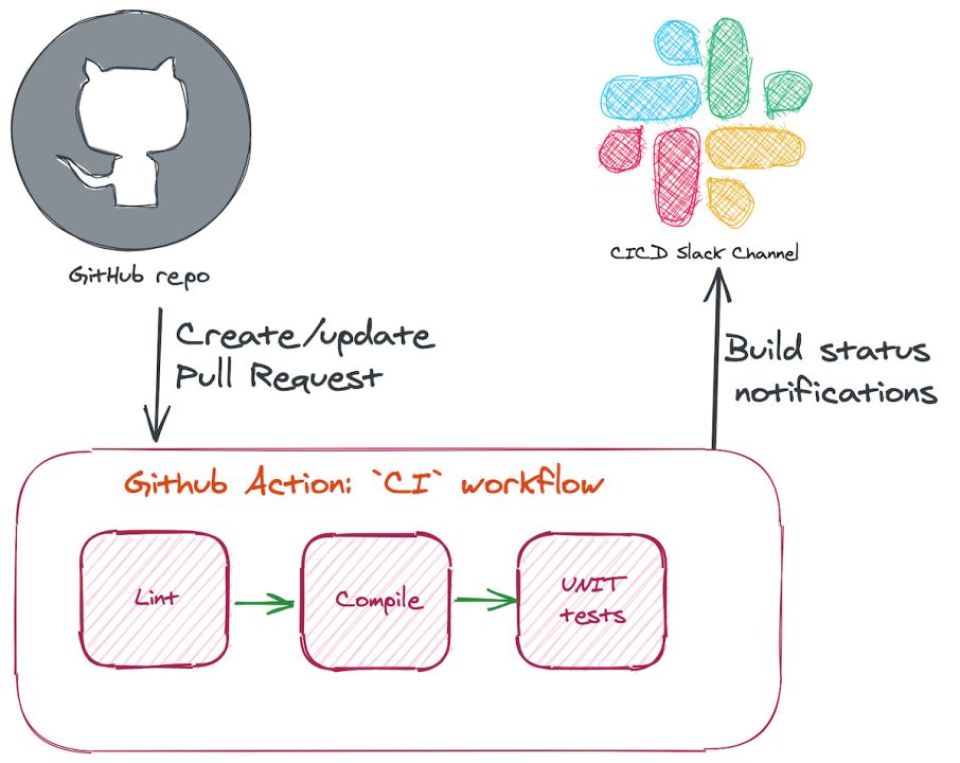
Kalau kamu pernah lihat status hijau kecil di pull request GitHub dan baru sadar betapa pentingnya tanda itu buat tim engineering, kamu sudah menyentuh inti dari topik ini. Pull request bukan cuma tempat orang saling review kode, tapi juga jadi pemicu utama yang menghidupkan seluruh mesin CI/CD di balik layar. Artikel ini bakal ngebahas gimana alur kerja CI/CD untuk pull request itu sebenarnya bekerja, kenapa dia jadi titik paling krusial dalam siklus rilis software modern, dan gimana kamu bisa membangunnya sendiri dari nol sampai siap dipakai tim.
Alur kerja CI/CD untuk pull request adalah rangkaian proses otomatis—mulai dari build, test, code review, sampai deploy ke lingkungan preview atau produksi—yang dijalankan setiap kali developer membuka atau memperbarui pull request di repositori Git.
Buat kamu yang sedang cari cara bikin pipeline yang benar-benar membantu, bukan sekadar formalitas, tulisan ini bakal jalan dari konsep dasar, tutorial teknis dengan contoh kode, perbandingan platform, sampai studi kasus nyata. Anggap saja ini panduan lengkap satu atap soal PR dan CI/CD.
Apa Itu Alur Kerja CI/CD untuk Pull Request?
Sebelum masuk lebih dalam, ada baiknya kita samakan dulu pemahaman soal dua istilah yang sering tertukar: Continuous Integration (CI) dan Continuous Delivery/Deployment (CD). CI adalah praktik menggabungkan perubahan kode dari banyak developer secara rutin sambil menjalankan pengujian otomatis, sementara CD adalah proses lanjutan yang menyiapkan—atau bahkan langsung merilis—kode tersebut ke lingkungan produksi.
Nah, pull request (PR) adalah "pintu masuk" resmi tempat kedua proses ini bertemu. Ketika seorang developer selesai mengerjakan fitur atau perbaikan bug di branch terpisah, mereka membuka PR untuk mengusulkan penggabungan kode itu ke branch utama, biasanya main atau master. Di titik inilah sistem CI/CD ambil alih.
Coba bayangkan begini: kalau pipeline CI/CD itu ibarat pabrik otomatis, maka pull request adalah tombol yang menyalakan seluruh lini produksi. Begitu tombol ditekan, serangkaian robot—linter, test runner, build server, scanner keamanan—langsung bergerak tanpa perlu disuruh satu-satu.
Kenapa PR Bukan Cuma Soal "Review Kode"
Dulu, pull request memang cuma dipakai untuk code review manual. Sekarang, perannya jauh lebih luas. Setiap kali PR dibuka, biasanya ada beberapa hal yang otomatis terjadi:
- Sistem CI mengambil kode dari branch terkait dan menjalankan proses build
- Unit test, integration test, sampai kadang end-to-end test dijalankan otomatis
- Alat analisis statis memeriksa potensi bug, kerentanan keamanan, atau pelanggaran standar coding
- Lingkungan preview atau staging bisa dibuat khusus untuk PR tersebut
- Status check dikirim kembali ke PR, biasanya berupa tanda centang hijau atau silang merah
Kalau salah satu tahapan gagal, tombol "Merge" biasanya langsung terkunci. Ini bukan cuma soal disiplin proses, tapi juga soal mencegah kode bermasalah masuk ke branch utama yang jadi sumber kebenaran untuk seluruh tim.
Kenapa Pull Request Jadi Titik Kritis di Pipeline CI/CD
Setelah beberapa tahun bergelut dengan berbagai pipeline—dari yang sederhana pakai shell script sampai yang penuh automasi dengan GitOps—saya bisa bilang dengan yakin bahwa PR adalah tempat paling strategis untuk menaruh "pagar pengaman" kualitas kode. Alasannya sederhana: di titik ini, kode belum masuk ke branch utama, jadi risiko masih bisa dikendalikan.
Ada tiga peran besar yang dimainkan pull request dalam ekosistem CI/CD:
1. Sebagai pemicu otomatisasi. Begitu event "PR dibuka" atau "PR diperbarui" terdeteksi lewat webhook, platform CI seperti GitHub Actions atau GitLab CI langsung menjalankan job yang sudah didefinisikan sebelumnya.
2. Sebagai gerbang kualitas (quality gate). PR menjadi tempat di mana hasil dari linter, test, dan scanner keamanan dikumpulkan. Kalau ada yang gagal, proses merge otomatis diblokir sampai masalahnya diperbaiki.
3. Sebagai pemicu deployment, terutama dalam model GitOps. Begitu PR disetujui dan digabung ke branch utama, tools seperti Argo CD atau Flux akan mendeteksi perubahan tersebut dan otomatis menyesuaikan kondisi di cluster produksi dengan apa yang tertulis di repositori.
Jadi, kalau ada yang bertanya "kenapa harus repot-repot bikin PR kalau cuma mau merge kode sendiri?", jawabannya jelas: karena PR bukan cuma soal formalitas kolaborasi, tapi fondasi dari seluruh mekanisme otomatisasi dan jaminan kualitas modern.
Anatomi Alur Kerja: Dari Branch Sampai Merge
Supaya lebih gampang dibayangkan, mari kita bedah alur kerja CI/CD untuk PR tahap demi tahap. Alur ini kira-kira sama di kebanyakan tim, meskipun detail toolingnya bisa berbeda-beda.
Tahap 1: Membuat Feature Branch
Semua bermula dari branch baru. Developer nggak langsung menulis kode di main, melainkan membuat cabang terpisah, biasanya dengan nama yang deskriptif seperti fix/login-error atau feature/checkout-baru. Ini penting supaya perubahan yang belum matang nggak mengganggu kestabilan kode yang sedang dipakai tim lain.
Tahap 2: Commit dan Push
Setelah kode ditulis dan diuji secara lokal, developer melakukan commit dengan pesan yang jelas, lalu push branch tersebut ke server pusat seperti GitHub, GitLab, atau Bitbucket. Di titik ini, kode sudah bisa dilihat tim, tapi belum tersentuh oleh pipeline CI.
Tahap 3: Membuka Pull Request
Di sinilah momen kunci terjadi. Developer membuka PR, menuliskan deskripsi perubahan, dan biasanya menandai reviewer yang relevan. Begitu PR terbuka, webhook otomatis terkirim ke sistem CI, dan pipeline mulai berjalan.
Tahap 4: Build dan Test Otomatis
Server CI mengambil kode dari branch PR, menjalankan proses build, lalu mengeksekusi berbagai jenis pengujian. Umumnya ada beberapa jenis tes yang dijalankan berurutan atau paralel:
- Unit test — memastikan fungsi-fungsi kecil bekerja sesuai ekspektasi
- Integration test — memverifikasi bahwa berbagai modul saling terhubung dengan benar
- Analisis kode statis (linting) — mendeteksi potensi bug atau pelanggaran gaya penulisan kode
- Security scan — memeriksa dependensi dan kode dari kerentanan yang sudah diketahui
Kalau semua lolos, PR akan menampilkan status hijau. Kalau ada yang gagal, developer akan menerima notifikasi lengkap dengan log error, sehingga mereka bisa langsung memperbaikinya tanpa harus menebak-nebak.
Tahap 5: Review Manusia
Meski otomatisasi sudah menangani banyak hal, review manusia tetap jadi bagian yang nggak tergantikan. Reviewer memeriksa logika bisnis, kejelasan kode, dan potensi masalah yang mungkin terlewat dari mesin. Di tahap ini, diskusi teknis biasanya terjadi lewat kolom komentar di PR.
Tahap 6: Preview atau Staging Environment (Opsional tapi Sangat Membantu)
Beberapa tim yang lebih matang membangun environment sementara khusus untuk setiap PR. Jadi, reviewer, desainer, atau bahkan product owner bisa langsung mengakses versi hidup dari perubahan tersebut lewat URL unik, tanpa harus menunggu kode di-merge dulu.
Tahap 7: Merge
Setelah semua status check hijau dan review disetujui, PR bisa digabung ke branch utama. Beberapa tim memilih merge manual, sementara yang lain mengaktifkan auto-merge begitu kondisi terpenuhi.
Tahap 8: Deploy ke Produksi
Tergantung strategi tim, deployment ke produksi bisa terjadi otomatis begitu merge selesai (continuous deployment), atau menunggu approval manual tambahan (continuous delivery). Dalam pendekatan GitOps, perubahan di branch utama otomatis "ditarik" oleh sistem yang memantau repositori dan disinkronkan ke cluster produksi.
Supaya lebih jelas, berikut tabel ringkas yang memetakan tiap tahap dengan tujuannya:
| Tahap | Tujuan Utama | Contoh Tools |
|---|---|---|
| Feature branch | Isolasi perubahan dari kode stabil | Git |
| Commit & push | Menyimpan progres ke repositori pusat | Git, GitHub, GitLab |
| Membuka PR | Memicu otomatisasi & memulai diskusi | GitHub, GitLab, Bitbucket |
| Build & test | Memverifikasi kualitas dan fungsi kode | GitHub Actions, GitLab CI, Jenkins |
| Review manusia | Menilai logika bisnis & kejelasan kode | GitHub Reviews, GitLab MR |
| Preview environment | Uji coba visual/fungsional sebelum merge | AWS CloudFormation, Vercel, Netlify |
| Merge | Menggabungkan kode ke branch utama | Git |
| Deploy | Merilis perubahan ke staging/produksi | Argo CD, Flux, AWS CodeDeploy |
Prasyarat Sebelum Membangun Alur Kerja CI/CD untuk PR
Sebelum kamu buru-buru menulis file YAML, ada beberapa hal yang wajib disiapkan dulu. Kalau ini dilewatkan, biasanya pipeline yang dibangun bakal rapuh dan gampang error di tengah jalan.
1. Repositori Git yang sudah terstruktur. Pastikan branch utama (main) dan strategi branching sudah disepakati tim, entah itu Git Flow, trunk-based development, atau model sederhana feature branch.
2. Akses ke platform CI/CD. Kamu butuh akun dengan izin yang cukup di GitHub Actions, GitLab CI, Jenkins, atau platform lain yang dipakai tim.
3. Skrip build dan test yang sudah berjalan lokal. Sebelum diotomatisasi, pastikan proses build dan test bisa dijalankan manual dulu di komputer kamu. Kalau di lokal saja sudah gagal, pipeline otomatis pasti ikut gagal.
4. Definisi environment variable dan secrets. Kredensial seperti API key, token database, atau sertifikat harus disiapkan dengan mekanisme penyimpanan rahasia (secrets manager), bukan ditulis langsung di kode.
5. Kesepakatan tim soal branch protection rules. Misalnya, apakah PR wajib disetujui minimal satu reviewer sebelum bisa di-merge, atau apakah status check tertentu wajib hijau dulu.
Kalau kelima poin ini sudah beres, kamu siap masuk ke bagian teknis.
Tutorial: Membuat Workflow CI untuk Pull Request dengan GitHub Actions
Bagian ini akan membahas langkah konkret membangun pipeline CI sederhana yang berjalan otomatis setiap kali PR dibuka. Saya pakai GitHub Actions sebagai contoh karena paling banyak dipakai dan gratis untuk repositori publik.
Langkah 1: Buat Folder Workflow
Di root repositori, buat folder .github/workflows/. Folder ini adalah tempat GitHub Actions membaca semua definisi pipeline.
mkdir -p .github/workflows
Kenapa ini penting: GitHub Actions hanya membaca file YAML yang ditaruh persis di lokasi ini. Kalau salah folder, workflow nggak akan pernah terdeteksi, dan kamu bisa bingung kenapa pipeline nggak jalan-jalan.
Langkah 2: Tulis File Workflow Dasar
Buat file .github/workflows/ci.yml dengan isi berikut:
name: CI untuk Pull Request
on:
pull_request:
branches: [main]
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- name: Checkout kode
uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
- name: Install dependencies
run: npm ci
- name: Jalankan linter
run: npm run lint
- name: Jalankan unit test
run: npm test
- name: Build proyek
run: npm run build
Kenapa struktur ini masuk akal: Trigger on: pull_request memastikan pipeline hanya jalan saat ada PR yang menyasar branch main, bukan setiap kali ada commit ke branch mana pun. Ini menghemat resource CI dan mempercepat feedback ke developer yang memang sedang menunggu hasil PR-nya.
Urutan step juga nggak asal. Checkout dulu, baru install dependency, baru lint, baru test, baru build. Kalau lint gagal, proses berhenti di situ dan nggak buang waktu menjalankan test yang lebih berat.
Langkah 3: Commit dan Push Workflow
git add .github/workflows/ci.yml
git commit -m "feat: tambah workflow CI untuk pull request"
git push origin nama-branch-kamu
Setelah push, buka pull request dari branch tersebut ke main. GitHub otomatis mendeteksi file workflow dan langsung menjalankannya.
Langkah 4: Cek Hasil di Tab "Checks"
Begitu PR terbuka, masuk ke tab Checks di halaman PR. Kamu akan melihat status berjalan (kuning), lalu berubah jadi hijau kalau semua lolos, atau merah kalau ada yang gagal.
Expected output kalau semua berjalan mulus, kira-kira seperti ini di log GitHub Actions:
Run npm test
> [email protected] test
> jest
PASS src/utils.test.js
PASS src/components/Button.test.js
Test Suites: 2 passed, 2 total
Tests: 14 passed, 14 total
Snapshots: 0 total
Time: 3.421s
Langkah 5: Tambahkan Branch Protection Rule
Supaya PR nggak bisa di-merge kalau status check gagal, masuk ke Settings > Branches > Branch protection rules di repositori GitHub, lalu aktifkan opsi "Require status checks to pass before merging" dan pilih job build-and-test.
Kenapa langkah ini krusial: Tanpa branch protection, siapa pun tetap bisa menekan tombol merge meskipun status check merah. Aturan ini yang benar-benar "mengunci" kualitas kode, bukan sekadar menampilkan indikator visual.
Kesalahan Umum dan Cara Mengatasinya
Berikut beberapa error yang sering muncul saat pertama kali menyiapkan pipeline seperti ini, beserta cara mengatasinya:
| Error | Kemungkinan Sebab | Solusi |
|---|---|---|
npm ci gagal dengan error lock file |
package-lock.json tidak sinkron dengan package.json |
Jalankan npm install di lokal, commit ulang lock file |
| Workflow tidak terpicu sama sekali | File YAML salah lokasi atau salah nama folder | Pastikan berada tepat di .github/workflows/ |
| Step "Setup Node.js" gagal | Versi Node yang diminta tidak tersedia di runner | Cek versi yang didukung di dokumentasi actions/setup-node |
| Test lolos di lokal tapi gagal di CI | Perbedaan environment variable atau timezone | Samakan environment variable, gunakan .env.example sebagai referensi |
| Job "menggantung" tanpa selesai | Ada proses yang menunggu input interaktif | Tambahkan flag non-interaktif, misalnya --yes atau CI=true |
Kalau kamu pernah ngalamin pipeline yang tiba-tiba merah padahal kode nggak diubah sama sekali, coba cek dulu apakah ada dependency yang baru rilis versi baru dan menyebabkan breaking change. Ini sering banget jadi jebakan tersembunyi, terutama di proyek yang tidak mengunci versi dependency dengan ketat.
Troubleshooting Lanjutan: Pipeline Lambat
Kalau pipeline kamu makin lama makin lambat, ada beberapa trik yang biasa saya pakai:
- Cache dependency. Gunakan
actions/cachesupayanode_modulesatau folder cache lain tidak diunduh ulang setiap kali PR baru dibuka. - Jalankan job secara paralel. Pisahkan lint, unit test, dan build jadi job terpisah yang berjalan bersamaan, bukan berurutan.
- Batasi trigger. Tambahkan filter path supaya workflow hanya jalan kalau file yang relevan berubah, misalnya cuma jalan kalau ada perubahan di folder
src/.
on:
pull_request:
branches: [main]
paths:
- "src/**"
- "package.json"
Trik kecil ini bisa memangkas waktu tunggu PR secara signifikan, apalagi di repositori besar dengan ratusan file yang jarang semuanya relevan dalam satu perubahan.
Perbandingan Platform CI/CD untuk Alur Kerja Pull Request
Ada banyak pilihan platform untuk menjalankan alur kerja CI/CD di PR, dan masing-masing punya karakter yang berbeda. Berikut perbandingan yang biasanya jadi pertimbangan tim saat memilih:
| Platform | Integrasi Git | Kurva Belajar | Cocok Untuk | Kelebihan Utama | Kekurangan Utama |
|---|---|---|---|---|---|
| GitHub Actions | Native di GitHub | Rendah–Menengah | Tim yang sudah pakai GitHub | Setup cepat, marketplace action luas | Bisa mahal untuk runner besar/self-hosted terbatas |
| GitLab CI/CD | Native di GitLab | Menengah | Tim yang pakai GitLab end-to-end | Fitur DevOps lengkap dalam satu platform | Kurang fleksibel kalau tim sudah nyaman di ekosistem lain |
| Jenkins | Plugin ke berbagai Git provider | Tinggi | Tim dengan kebutuhan kustomisasi tinggi | Sangat fleksibel, banyak plugin | Perlu maintenance server sendiri |
| Azure DevOps Pipelines | Terintegrasi dengan Azure Repos, bisa juga GitHub | Menengah | Perusahaan yang sudah pakai ekosistem Microsoft | Terintegrasi rapi dengan Azure | Kurang populer di komunitas open source |
| CircleCI | Terhubung ke GitHub/Bitbucket | Rendah–Menengah | Tim kecil–menengah yang butuh kecepatan setup | Performa build cepat | Free tier terbatas untuk tim besar |
Kriteria yang Perlu Dipertimbangkan
Saat memilih platform, jangan cuma lihat popularitasnya. Beberapa kriteria yang lebih relevan buat kebutuhan jangka panjang:
- Kompatibilitas dengan Git provider yang sudah dipakai tim. Kalau kamu sudah pakai GitHub, GitHub Actions biasanya jadi pilihan paling masuk akal karena minim friction.
- Kebutuhan self-hosted runner. Kalau ada regulasi data yang mengharuskan build berjalan di infrastruktur internal, Jenkins atau self-hosted runner GitLab bisa jadi lebih cocok.
- Anggaran. Biaya runner cloud bisa membengkak seiring banyaknya PR yang dibuka tim, terutama untuk repositori dengan trafik commit tinggi.
- Kebutuhan integrasi dengan tools lain, seperti Slack, Jira, atau ClickUp untuk notifikasi status build.
Rekomendasi Berdasarkan Skenario
- Startup kecil dengan tim di bawah 10 orang: GitHub Actions biasanya paling efisien karena setup cepat dan gratis untuk kebutuhan dasar.
- Perusahaan dengan kebutuhan compliance ketat: Jenkins self-hosted atau Azure DevOps Pipelines lebih aman karena kontrol penuh atas infrastruktur.
- Tim yang sudah full di ekosistem GitLab: GitLab CI/CD jelas jadi pilihan alami karena semuanya sudah terintegrasi tanpa perlu tools tambahan.
- Tim mobile (Flutter, React Native): GitHub Actions dikombinasikan dengan Fastlane sering jadi kombinasi favorit karena dukungan komunitas yang luas untuk build iOS dan Android.
Review Mendalam: Otomatisasi CI/CD di Pull Request, Worth It atau Tidak?
Sekarang mari kita bahas dari sudut pandang yang lebih reflektif—apakah investasi waktu membangun pipeline PR ini benar-benar sepadan?
Overview
Otomatisasi CI/CD di level pull request pada dasarnya adalah investasi di awal yang membayar dirinya sendiri lewat pengurangan bug produksi, mempercepat proses review, dan mengurangi beban mental developer yang nggak perlu lagi mengecek semua hal secara manual.
Fitur-Fitur Kunci yang Biasanya Dicari Tim
- Status check otomatis yang terintegrasi langsung di halaman PR
- Kemampuan menjalankan test secara paralel untuk mempercepat feedback
- Dukungan matrix testing (menguji di beberapa versi bahasa/framework sekaligus)
- Integrasi notifikasi ke Slack atau email saat build gagal
- Kemampuan membuat preview environment otomatis per PR
Studi Penggunaan Nyata
Tim mobile yang merilis aplikasi setiap minggu biasanya membangun alur kerja yang menjalankan linting, format check, dan seluruh test suite setiap kali PR dibuka, sebelum lanjut ke proses build artefak Android dan iOS. Begitu build berhasil, sistem otomatis mengirim notifikasi lengkap dengan link artefak ke task management tool yang mereka pakai, sehingga tim QA bisa langsung mengunduh dan mengujinya tanpa menunggu developer selesai kerja manual.
Di skala yang lebih besar, tim yang mengelola infrastruktur cloud sering membangun preview environment penuh untuk setiap PR, lengkap dengan database dan konfigurasi yang meniru produksi. Ini memungkinkan desainer dan product owner memberi feedback lebih awal, bukan setelah kode sudah di-merge dan sulit diubah lagi.
Kelebihan
- Mempercepat feedback loop. Developer tahu ada masalah dalam hitungan menit, bukan hari.
- Mengurangi risiko human error. Proses yang berulang seperti test dan build nggak lagi bergantung pada ketelitian manual.
- Meningkatkan kepercayaan tim terhadap kode yang di-merge. Kalau status check hijau, tim lebih percaya diri kode tersebut aman digabung.
- Menjadi jejak audit yang rapi. Setiap perubahan tercatat, tervalidasi, dan bisa dilacak siapa yang menyetujui apa.
- Memungkinkan rollback cepat. Kalau ada masalah di produksi, tinggal revert PR dan pipeline otomatis mengembalikan kondisi sebelumnya.
Kekurangan
- Butuh waktu setup di awal. Buat tim yang belum familiar, menyiapkan pipeline yang benar bisa makan waktu beberapa hari sampai minggu.
- Biaya infrastruktur bisa membengkak. Semakin sering PR dibuka, semakin banyak resource compute yang terpakai.
- Berisiko menjadi terlalu kompleks. Kalau nggak dijaga, pipeline bisa berkembang jadi rumit dan sulit di-maintain oleh anggota tim baru.
- False sense of security. Status hijau di CI bukan garansi kode bebas bug total, cuma menandakan test yang ada sudah lolos.
Siapa yang Paling Cocok Pakai Ini
Tim dengan lebih dari satu developer aktif, frekuensi rilis yang cukup sering, dan kode yang berdampak langsung ke pengguna akhir adalah kandidat paling ideal. Kalau kamu mengelola proyek yang dipakai banyak orang dan perubahan kecil saja bisa berdampak besar, alur kerja ini bukan pilihan, tapi kebutuhan.
Siapa yang Sebaiknya Menunda
Proyek personal yang masih dikerjakan sendirian dan belum punya user nyata mungkin belum perlu pipeline yang rumit. Terlalu dini membangun otomasi yang berat justru bisa menghabiskan waktu yang lebih baik dipakai untuk mengembangkan fitur inti dulu.
Verdict
Kalau ditanya apakah alur kerja CI/CD untuk PR ini layak diinvestasikan, jawaban saya jelas: ya, terutama begitu tim sudah lebih dari satu orang. Yang perlu diingat, mulai dari yang sederhana dulu—linting dan unit test saja sudah cukup di awal—baru berkembang ke arah yang lebih canggih seperti preview environment dan deployment otomatis.
Studi Kasus: Memangkas Waktu Review dengan Preview Environment per Pull Request
Beberapa waktu lalu, saya terlibat membantu sebuah tim kecil yang kesulitan dengan proses review fitur baru di aplikasi web mereka. Saya bagikan pengalaman ini karena pola masalahnya cukup umum dan kemungkinan besar relate dengan situasi banyak tim lain.
Latar Belakang
Tim ini terdiri dari lima developer yang mengerjakan aplikasi berbasis web dengan rilis mingguan. Proses review waktu itu masih mengandalkan developer menjalankan branch teman mereka secara lokal untuk melihat perubahan visual, yang tentu saja ribet dan rawan salah konfigurasi environment.
Masalah yang Dihadapi
Setiap kali ada PR yang menyangkut perubahan tampilan atau interaksi pengguna, reviewer harus:
- Checkout branch tersebut secara manual
- Install dependency yang kadang berbeda dari branch utama
- Menjalankan aplikasi secara lokal, yang kadang gagal karena environment variable belum disesuaikan
- Baru bisa memberi feedback setelah semua langkah di atas berhasil
Prosesnya bisa menghabiskan waktu 20-30 menit hanya untuk melihat perubahan yang sebenarnya sederhana. Akibatnya, banyak PR menumpuk tanpa review karena reviewer menunda-nunda proses yang merepotkan ini.
Pendekatan yang Diambil
Solusinya adalah membangun preview environment otomatis untuk setiap PR, memanfaatkan infrastruktur sebagai kode yang sudah mereka punya lewat Serverless Framework dan AWS CloudFormation. Setiap PR diperlakukan sebagai stage baru, terpisah dari environment staging dan produksi yang sudah ada.
Implementasi
Tim menambahkan job baru di pipeline Azure DevOps yang otomatis membuat stage baru menggunakan ID pull request sebagai identitas unik, misalnya pr-565. Beberapa komponen yang berat dan tidak dibutuhkan untuk preview, seperti distribusi CloudFront yang butuh waktu deployment cukup lama, dibuat opsional lewat environment variable, supaya proses deploy preview jauh lebih cepat dibanding deploy ke staging penuh.
Setelah deployment preview berhasil, pipeline otomatis memposting URL unik langsung di kolom komentar pull request, sehingga reviewer, desainer, dan product owner bisa langsung mengklik dan melihat hasilnya tanpa setup apa pun di komputer masing-masing.
Tim juga menambahkan script pembersihan otomatis yang berjalan setiap hari, memeriksa PR mana yang masih terbuka lewat API Git, lalu menghapus environment preview milik PR yang sudah ditutup atau di-merge. Ini penting supaya jumlah resource cloud yang aktif tidak terus menumpuk tanpa terkontrol.
Hasil
Setelah preview environment ini berjalan sekitar dua bulan, beberapa perubahan yang terasa cukup signifikan:
- Waktu rata-rata review PR yang menyangkut tampilan turun dari sekitar 25 menit menjadi kurang dari 5 menit
- Jumlah PR yang menunggu review lebih dari 2 hari berkurang drastis karena reviewer nggak lagi malas membuka PR
- Feedback dari product owner datang lebih cepat, bahkan sebelum kode di-merge, sehingga mengurangi PR "revisi ulang" yang sebelumnya sering terjadi
- Biaya cloud sedikit meningkat karena resource tambahan, tapi masih jauh lebih murah dibanding waktu developer yang terselamatkan
Pelajaran yang Bisa Diambil
Dari pengalaman ini, ada beberapa hal yang menurut saya penting dicatat:
- Kecepatan feedback lebih berharga daripada kelengkapan environment. Preview yang sedikit disederhanakan tapi cepat jauh lebih berguna dibanding preview lengkap yang butuh waktu lama untuk siap.
- Pembersihan otomatis wajib ada dari awal, bukan ditambahkan belakangan setelah resource menumpuk dan biaya membengkak.
- Kolaborasi lintas peran meningkat drastis begitu non-developer bisa ikut memberi masukan lebih awal, tanpa harus menunggu kode masuk ke staging resmi.
Ketika Tim Belum Punya Alur Kerja CI/CD yang Rapi: Masalah dan Solusinya
Banyak tim, terutama yang baru berkembang, sering mengalami gejala yang mirip satu sama lain sebelum akhirnya sadar butuh alur kerja CI/CD yang lebih terstruktur untuk PR mereka.
Masalah yang Sering Muncul
- Bug lolos ke produksi padahal "sudah ditest manual". Karena testing manual gampang terlewat, apalagi kalau developer sedang buru-buru deadline.
- Proses review jadi bottleneck. PR menumpuk karena reviewer harus setup environment secara manual setiap kali mau melihat perubahan.
- Konflik antar developer soal gaya penulisan kode. Tanpa linter otomatis, diskusi soal format kode sering menghabiskan waktu review yang seharusnya fokus ke logika bisnis.
- Rilis jadi momen menegangkan. Karena nggak ada jaminan otomatis, setiap rilis serasa pertaruhan apakah semuanya akan berjalan lancar atau justru berantakan di produksi.
Kenapa Ini Harus Segera Dibenahi
Masalah-masasalah di atas kelihatannya kecil satu-satu, tapi efeknya kumulatif. Semakin lama dibiarkan, semakin besar juga "utang teknis" yang menumpuk, dan semakin sulit juga membenahinya di kemudian hari karena kebiasaan tim sudah terbentuk.
Selain itu, dari sisi bisnis, keterlambatan rilis fitur karena proses manual yang lambat berarti kehilangan momentum kompetitif. Di pasar yang bergerak cepat, kecepatan iterasi produk sering jadi pembeda antara tim yang unggul dan yang tertinggal.
Pendekatan Solusi
Solusinya nggak harus langsung membangun sistem yang rumit. Pendekatan yang lebih realistis biasanya bertahap:
- Mulai dengan otomatisasi linting dan unit test dasar di setiap PR
- Tambahkan branch protection rule supaya status check wajib hijau sebelum merge
- Perkenalkan integration test begitu unit test sudah stabil
- Bangun preview environment kalau tim sering butuh feedback visual
- Terapkan continuous deployment begitu tim sudah percaya diri dengan cakupan test yang ada
Manfaat yang Akan Dirasakan
Begitu alur kerja ini berjalan konsisten, tim biasanya merasakan beberapa manfaat nyata:
- Waktu dari "kode selesai" sampai "kode live di produksi" jadi lebih singkat dan bisa diprediksi
- Developer lebih berani melakukan refactor karena ada jaring pengaman otomatis
- Diskusi review jadi lebih berkualitas karena nggak lagi terbuang untuk hal-hal teknis kecil yang seharusnya bisa dideteksi mesin
Cara Menyusun Pipeline Pull Request dari Nol
Bagian ini saya susun sebagai panduan praktis yang bisa langsung kamu jalankan, terlepas dari platform apa yang dipakai tim kamu.
Step 1: Petakan Alur Kerja Git Tim Kamu
Sebelum menyentuh konfigurasi CI, pastikan tim sudah sepakat soal strategi branching. Apakah pakai trunk-based development dengan branch pendek, atau Git Flow dengan branch develop terpisah? Keputusan ini akan menentukan bagaimana trigger pipeline nantinya diatur.
Step 2: Tentukan Definisi "Selesai" untuk Setiap PR
Sepakati bersama tim, syarat apa yang harus terpenuhi sebelum PR dianggap layak di-merge. Biasanya mencakup: semua test lolos, minimal satu approval, dan tidak ada konflik dengan branch utama.
Step 3: Bangun Pipeline Minimum yang Berfungsi
Jangan langsung berambisi membangun sistem yang lengkap. Mulai dengan pipeline yang menjalankan install dependency, lint, dan test. Ini sudah cukup untuk menangkap sebagian besar masalah umum.
Step 4: Tambahkan Branch Protection
Aktifkan aturan yang mewajibkan status check lolos sebelum merge diizinkan. Tanpa langkah ini, pipeline yang sudah dibangun cuma jadi informasi, bukan penjaga kualitas yang sesungguhnya.
Step 5: Perluas dengan Integration dan Security Test
Setelah pipeline dasar stabil selama beberapa minggu, tambahkan integration test untuk memverifikasi interaksi antar modul, dan security scan untuk memeriksa dependensi yang rentan.
Step 6: Pertimbangkan Preview Environment
Kalau proyek kamu punya komponen visual atau UX yang penting untuk direview langsung, investasikan waktu membangun preview environment otomatis. Ini akan sangat membantu kolaborasi lintas peran, terutama dengan desainer dan product owner.
Step 7: Otomatiskan Deployment Setelah Merge
Begitu kepercayaan terhadap test coverage sudah cukup tinggi, mulai otomatiskan deployment ke staging, lalu produksi. Pertimbangkan pendekatan canary release atau blue-green deployment untuk mengurangi risiko rilis besar sekaligus.
Step 8: Pantau dan Iterasi
Pasang monitoring untuk melihat metrik pipeline itu sendiri, seperti berapa lama rata-rata waktu build, seberapa sering test gagal, dan berapa lama rata-rata PR menunggu review. Data ini akan membantu kamu tahu bagian mana dari alur kerja yang masih perlu dibenahi.
Tips Tambahan Biar Pipeline Nggak Berantakan
- Jangan biarkan pipeline jadi terlalu panjang dan monolitik. Pecah jadi job-job kecil yang jelas tanggung jawabnya, supaya lebih mudah dilacak kalau ada yang gagal.
- Gunakan cache secara bijak untuk mempercepat proses install dependency yang berulang.
- Batalkan job lama kalau ada push baru ke branch yang sama, supaya nggak buang-buang resource menjalankan build yang sudah usang.
- Dokumentasikan pipeline kamu, minimal lewat komentar di file konfigurasi, supaya anggota tim baru nggak bingung saat harus mengubahnya.
- Review ulang pipeline secara berkala, misalnya setiap kuartal, untuk menghapus step yang sudah nggak relevan atau mengganti tools yang sudah usang.
Keamanan di Pipeline PR yang Sering Dilewatkan
Banyak tim udah bangga pipeline-nya jalan mulus, test hijau semua, tapi lupa satu hal penting: keamanan. Padahal pull request adalah titik paling rawan buat kebocoran informasi sensitif, karena di sinilah kode dari banyak orang—termasuk kontributor luar kalau proyeknya open source—ketemu dengan sistem yang punya akses ke secrets dan infrastruktur produksi.
Beberapa hal yang wajib kamu perhatikan biar pipeline PR nggak jadi pintu belakang buat masalah keamanan:
1. Jangan pernah expose secrets ke fork eksternal. Kalau proyek kamu open source dan menerima PR dari fork, hati-hati sama trigger pull_request_target di GitHub Actions. Trigger ini punya akses ke secrets repositori utama, padahal kode yang dijalankan berasal dari fork yang belum tentu bisa dipercaya. Kalau nggak dikonfigurasi dengan benar, ini bisa dimanfaatkan buat mencuri token atau kredensial lain.
2. Pin versi action ke commit hash, bukan cuma tag. Tag seperti @v4 bisa berubah isinya kalau maintainer action tersebut update rilisnya tanpa bikin versi baru. Kalau kamu mau lebih aman, pakai commit SHA penuh, misalnya actions/checkout@a1b2c3d..., biar nggak ada kejutan tiba-tiba dari dependency pihak ketiga.
3. Terapkan dependency scanning otomatis. Tools seperti Dependabot, Snyk, atau npm audit bisa dijadwalkan jalan setiap PR dibuka, supaya kerentanan di library pihak ketiga ketahuan sebelum kode itu masuk ke branch utama. Ini jauh lebih murah dibanding nunggu sampai ada insiden keamanan di produksi.
4. Pakai static application security testing (SAST). Tools seperti CodeQL atau Semgrep bisa dijalankan otomatis di setiap PR buat mendeteksi pola kode yang berpotensi rentan, misalnya SQL injection atau penanganan input yang kurang aman. Enaknya, hasil scan ini biasanya langsung muncul sebagai komentar di baris kode yang bermasalah, jadi developer nggak perlu buka tools terpisah.
5. Terapkan prinsip least privilege buat token CI. Token yang dipakai pipeline sebaiknya cuma punya izin seminimal yang dibutuhkan. Kalau pipeline cuma perlu baca kode dan menulis status check, jangan kasih izin admin penuh ke repositori. Ini bakal membatasi dampak kalau suatu saat ada kebocoran token.
Poin-poin ini kelihatan teknis, tapi efeknya besar. Saya pernah lihat sendiri tim yang kelewat santai soal ini, dan begitu ada satu PR dari kontributor luar yang ternyata berisi script jahat, untungnya ketahuan karena scanner otomatis langsung menandai perilaku aneh sebelum sempat di-merge. Kalau nggak ada lapisan keamanan ini, ceritanya bisa jauh lebih rumit.
Strategi Merge: Squash, Rebase, atau Merge Commit?
Setelah PR disetujui, ada satu keputusan kecil yang sering dianggap sepele tapi sebenarnya berdampak ke kerapian riwayat kode: cara PR digabung ke branch utama. Ada tiga opsi umum yang biasanya tersedia di platform seperti GitHub, dan masing-masing punya konsekuensi berbeda buat histori commit.
| Strategi | Cara Kerja | Kelebihan | Kekurangan |
|---|---|---|---|
| Squash and merge | Semua commit di PR digabung jadi satu commit tunggal di branch utama | Riwayat commit di main jadi bersih dan mudah dibaca |
Detail histori kecil per commit di PR jadi hilang |
| Merge commit | Semua commit dari branch PR dipertahankan, ditambah satu commit merge baru | Histori lengkap tetap terjaga, termasuk konteks per commit | Riwayat main bisa jadi berantakan kalau developer sering commit kecil-kecil |
| Rebase and merge | Commit dari PR ditempel ulang di atas branch utama tanpa commit merge tambahan | Riwayat tetap linear tanpa commit merge yang mengganggu | Berisiko konflik lebih rumit kalau branch utama sudah banyak berubah |
Dari pengalaman saya, squash and merge biasanya jadi pilihan paling nyaman buat tim yang mengutamakan kerapian, apalagi kalau kebiasaan commit developer di tim masih berantakan—banyak commit dengan pesan seperti "fix typo" atau "coba lagi". Squash bikin semua "kekacauan" itu ringkas jadi satu commit yang jelas.
Sebaliknya, kalau tim kamu sudah disiplin soal pesan commit dan ingin menjaga jejak histori yang detail—misalnya buat kebutuhan audit atau debugging yang butuh granularitas tinggi—merge commit bisa jadi pilihan yang lebih masuk akal.
Rebase biasanya dipilih tim yang benar-benar mengutamakan riwayat linear tanpa cabang-cabang kecil yang membingungkan, tapi ini butuh kedisiplinan lebih karena konflik rebase kadang lebih sulit diselesaikan dibanding konflik merge biasa.
Nggak ada jawaban benar-salah di sini. Yang penting, sepakati satu strategi di level tim dan konsisten memakainya, supaya histori kode nggak jadi campur aduk karena setiap orang pakai cara yang beda-beda.
Mengukur Efektivitas Pipeline PR Lewat Metrik DORA
Kalau kamu sudah menjalankan pipeline PR selama beberapa bulan, pertanyaan berikutnya yang wajar muncul adalah: gimana cara tahu pipeline ini benar-benar efektif, bukan cuma bikin developer sibuk nunggu status check? Di sinilah metrik DORA (DevOps Research and Assessment) bisa jadi alat ukur yang membantu.
Ada empat metrik utama yang biasa dipakai:
- Deployment frequency — seberapa sering tim merilis perubahan ke produksi. Pipeline PR yang sehat biasanya berkorelasi dengan frekuensi rilis yang lebih tinggi, karena setiap perubahan sudah diverifikasi otomatis dan nggak perlu menunggu proses manual yang panjang.
- Lead time for changes — berapa lama waktu dari kode pertama kali di-commit sampai benar-benar live di produksi. Pipeline PR yang efisien akan memangkas angka ini secara signifikan, karena proses build, test, dan review nggak lagi jadi bottleneck.
- Change failure rate — persentase perubahan yang menyebabkan masalah di produksi, entah itu bug, downtime, atau butuh rollback. Kalau quality gate di PR benar-benar berfungsi, angka ini seharusnya menurun dari waktu ke waktu.
- Time to restore service — berapa lama waktu yang dibutuhkan buat memulihkan layanan setelah terjadi insiden. Pipeline yang mendukung rollback cepat—misalnya lewat revert PR yang otomatis memicu deployment ulang—bisa memangkas metrik ini drastis.
Cara paling praktis buat mulai memantau ini adalah dengan mencatat timestamp di setiap tahap pipeline: kapan PR dibuka, kapan status check selesai, kapan merge terjadi, dan kapan deployment ke produksi benar-benar rampung. Beberapa platform CI sudah punya dashboard bawaan buat ini, tapi kalau belum ada, kamu bisa saja mengekspor data lewat API dan menyusunnya sendiri di spreadsheet atau tools visualisasi sederhana.
Yang perlu diingat, metrik ini bukan buat "menghukum" developer yang lambat, tapi buat melihat pola di level sistem. Kalau lead time tiba-tiba melonjak, mungkin bukan karena developer jadi ceroboh, tapi karena ada step di pipeline yang jadi bottleneck baru, misalnya test suite yang makin gemuk atau antrian runner yang penuh.
Studi Kasus: Tim Backend yang Menekan Bug Produksi Lewat Contract Testing di PR
Selain cerita soal preview environment yang sudah saya bahas sebelumnya, ada satu pengalaman lain yang menurut saya sama pentingnya buat dibagikan, terutama buat tim yang bekerja dengan arsitektur microservices.
Latar Belakang
Sebuah tim backend yang saya bantu waktu itu mengelola belasan service kecil yang saling berkomunikasi lewat REST API. Setiap service dikembangkan oleh sub-tim yang berbeda, dan masalahnya baru kelihatan setelah semuanya digabung: satu service mengubah format response API tanpa sadar kalau service lain masih mengandalkan format lama.
Masalah yang Dihadapi
Unit test di masing-masing service lolos semua, karena memang cuma menguji service itu sendiri secara terisolasi. Masalahnya baru muncul saat semua service dijalankan bersamaan di staging, dan seringnya ketahuan justru setelah deployment ke produksi. Ini bikin insiden berulang, dan setiap kali terjadi, butuh waktu lama buat melacak service mana yang jadi sumber masalah karena banyaknya service yang saling terhubung.
Pendekatan yang Diambil
Tim ini akhirnya mengadopsi contract testing menggunakan Pact, dengan tujuan memastikan kontrak antara consumer dan provider API tetap konsisten, dan pengecekan ini dijalankan otomatis di setiap PR, bukan cuma saat staging.
Cara kerjanya kira-kira begini: setiap service yang jadi "consumer" mendefinisikan ekspektasi format response yang mereka butuhkan dari service "provider". Ekspektasi ini disimpan sebagai file kontrak yang dipublikasikan ke broker khusus. Setiap kali ada PR yang mengubah kode provider, pipeline otomatis mengambil kontrak yang sudah didefinisikan consumer, lalu memverifikasi apakah perubahan tersebut masih memenuhi ekspektasi itu.
Implementasi
Tim menambahkan job baru di pipeline CI mereka, khusus buat menjalankan verifikasi kontrak sebelum tahap merge diizinkan. Kalau ada perubahan yang melanggar kontrak—misalnya field yang dihapus atau tipe data yang berubah tanpa pemberitahuan—PR langsung ditandai gagal, lengkap dengan detail kontrak mana yang dilanggar dan consumer mana yang terdampak.
Yang menarik, tim juga menerapkan aturan bahwa provider nggak bisa deploy ke produksi kalau ada kontrak yang belum terverifikasi, lewat mekanisme yang mereka sebut "can-i-deploy" check. Jadi bukan cuma soal PR yang harus hijau, tapi juga soal kepastian bahwa versi yang mau dirilis benar-benar kompatibel dengan semua consumer yang aktif.
Hasil
Setelah beberapa bulan berjalan, dampaknya cukup kelihatan:
- Insiden yang disebabkan oleh perubahan API yang nggak kompatibel turun drastis, dari yang sebelumnya rutin terjadi hampir setiap rilis
- Developer di tim consumer nggak perlu lagi menunggu sampai staging buat tahu apakah perubahan provider akan berdampak ke mereka
- Diskusi antar tim jadi lebih terarah, karena begitu ada pelanggaran kontrak, semua orang bisa langsung lihat detail teknisnya di PR, bukan cuma saling lempar tanggung jawab saat insiden terjadi
Pelajaran yang Bisa Diambil
Dari kasus ini, saya belajar bahwa unit test yang lolos semua bukan garansi sistem aman, terutama di arsitektur yang banyak service saling bergantung. Verifikasi di level integrasi antar service itu penting, dan yang paling ideal, verifikasi itu terjadi secepat mungkin—idealnya di level PR, bukan menunggu sampai staging atau bahkan produksi.
Pertanyaan yang Sering Muncul soal Alur Kerja CI/CD untuk PR
Berdasarkan pengalaman mendampingi beberapa tim membangun pipeline serupa, ada beberapa pertanyaan yang hampir selalu muncul. Berikut jawabannya, biar kamu nggak perlu mencari-cari sendiri di forum atau dokumentasi yang bertebaran.
Apakah proyek kecil dengan satu developer tetap butuh pipeline CI/CD untuk PR?
Kalau kamu benar-benar bekerja sendirian dan belum ada user nyata yang bergantung pada aplikasi tersebut, pipeline yang rumit mungkin belum jadi prioritas. Tapi kalau proyek itu sudah dipakai orang lain, atau kamu berencana mengajak kolaborator, ada baiknya mulai dari yang sederhana—cukup linting dan unit test otomatis di setiap PR—biar kebiasaan baik ini sudah terbentuk sebelum tim berkembang.
Berapa lama waktu ideal untuk satu pipeline CI berjalan?
Nggak ada angka pasti yang berlaku universal, tapi patokan umum yang sering dipakai adalah di bawah 10 menit untuk feedback awal seperti lint dan unit test. Kalau pipeline kamu sudah melebihi 15-20 menit, developer biasanya mulai kehilangan fokus atau beralih ke tugas lain sambil menunggu, dan itu bisa bikin proses review jadi tertunda.
Apa bedanya pipeline yang jalan di PR dengan pipeline yang jalan di branch utama?
Pipeline di PR biasanya fokus ke verifikasi—memastikan kode yang diusulkan aman untuk digabung, tanpa benar-benar mengubah apa pun di lingkungan produksi. Sementara pipeline di branch utama biasanya jadi titik awal proses deployment, entah ke staging atau langsung ke produksi, tergantung strategi CD yang dipakai tim.
Apakah semua PR wajib melalui preview environment?
Nggak selalu perlu. Preview environment paling bermanfaat buat perubahan yang punya dampak visual atau interaksi pengguna, seperti perubahan UI atau flow baru. Untuk perubahan kecil seperti update dokumentasi, perbaikan konfigurasi, atau refactor internal yang nggak mengubah perilaku aplikasi, preview environment biasanya cuma buang-buang resource tanpa manfaat sepadan.
Bagaimana menangani PR yang mengubah banyak file sekaligus dan bikin pipeline lama?
Kalau memungkinkan, dorong kebiasaan membuat PR yang lebih kecil dan fokus pada satu perubahan spesifik. PR besar bukan cuma bikin pipeline lebih lama, tapi juga bikin review manusia jadi lebih berat dan rawan melewatkan detail penting. Kalau perubahan besar memang nggak terhindarkan, pertimbangkan memecahnya jadi beberapa PR bertahap yang masing-masing tetap bisa berjalan mandiri.
Checklist Praktis Sebelum Meluncurkan Pipeline PR ke Tim
Sebelum mengumumkan ke seluruh tim bahwa pipeline CI/CD untuk PR sudah siap dipakai, ada baiknya cek dulu beberapa hal ini, biar peluncurannya nggak bikin kaget atau malah menghambat kerja tim di hari-hari awal.
- Pipeline sudah diuji di beberapa PR percobaan, bukan cuma di lingkungan lokal kamu sendiri
- Waktu eksekusi pipeline sudah masuk akal, idealnya di bawah 10-15 menit untuk feedback dasar
- Branch protection rule sudah aktif dan status check yang wajib sudah dipilih dengan benar
- Semua developer di tim sudah tahu cara membaca log kalau ada step yang gagal
- Ada dokumentasi singkat, minimal di README, soal apa saja yang dicek pipeline dan bagaimana cara menjalankannya secara lokal kalau perlu debug
- Secrets dan token yang dipakai pipeline sudah disimpan lewat mekanisme yang aman, bukan hardcoded di file konfigurasi
- Ada rencana pembersihan otomatis kalau pipeline membuat resource sementara seperti preview environment
- Tim sudah sepakat soal strategi merge yang dipakai, biar histori kode tetap konsisten
Checklist ini nggak harus semuanya terpenuhi 100% sebelum diluncurkan, tapi minimal poin-poin soal branch protection dan keamanan secrets itu wajib ada dari hari pertama. Sisanya bisa disempurnakan sambil jalan, apalagi kalau tim kamu masih dalam fase belajar membangun kebiasaan baru seputar PR dan otomatisasi.
Satu hal yang saya sering sarankan ke tim yang baru mulai: jangan langsung menuntut pipeline yang sempurna dari awal. Biarkan tim merasakan dulu manfaat dari otomatisasi sederhana, baru bertahap menambah lapisan pengujian dan otomatisasi begitu kepercayaan terhadap prosesnya makin terbentuk. Pipeline yang dibangun terlalu ambisius di awal justru sering berakhir ditinggalkan karena terlalu rumit buat dipelihara oleh tim yang belum siap.
Kesimpulan
Membangun alur kerja CI/CD untuk pull request bukan sekadar soal memasang beberapa command di file YAML, tapi soal membentuk kebiasaan tim dalam menjaga kualitas kode sejak baris pertama diajukan untuk direview. Preview environment, branch protection, dan status check yang wajib lolos semuanya punya peran masing-masing, tapi kekuatan sebenarnya muncul saat semua elemen itu bekerja bersama sebagai lapisan pengaman yang konsisten, bukan sebagai formalitas yang dilewati begitu saja.
Yang sering terlewat oleh tim yang baru mulai adalah bahwa pipeline yang baik nggak harus langsung lengkap dan canggih. Justru pipeline yang terlalu ambisius di awal cenderung berakhir ditinggalkan karena sulit dirawat. Lebih baik mulai dari fondasi yang sederhana namun solid, seperti keamanan secrets dan branch protection yang aktif dari hari pertama, lalu biarkan tim merasakan manfaatnya dulu sebelum menambah lapisan pengujian yang lebih kompleks.
Checklist praktis yang sudah dibahas bisa jadi titik awal yang realistis, bukan daftar yang harus 100% tercapai sebelum pipeline dianggap layak dipakai. Yang lebih penting adalah komitmen tim untuk terus menyempurnakannya secara bertahap, sambil belajar dari PR-PR nyata yang berjalan setiap hari.
Kalau tim kamu belum punya pipeline CI/CD untuk PR sama sekali, sekarang adalah waktu yang tepat untuk memulai dari versi paling sederhana. Jangan tunggu sampai proyek makin besar dan kebiasaan buruk makin sulit diubah, karena setiap PR yang lolos tanpa pengecekan otomatis hari ini adalah utang teknis yang harus dibayar tim kamu di kemudian hari.
Referensi
CloudQubes. (2026). Decoding the Pull Request: The Master Switchboard of Modern CI/CD.
Google Cloud. (2026). Penggunaan dan Alur Kerja CI/CD Looker.
AWS. (2026). Apa itu Jalur CI/CD?
Medium. (2026). Level Up Your CI/CD Pipeline with PR Deployments.
IBM. (2026). Apa itu Pull Request?
ClickUp. (2026). Flutter CI dan CD di ClickUp.
Morfotech. (2026). Membangun CI/CD Pipeline yang Efisien: Panduan Lengkap untuk Pemula hingga Mahir.
Microsoft Learn. (2026). Alur Kerja CI/CD Menggunakan GitOps (Flux v2).
Scribd. (2026). Peran Repositori dalam CI/CD.
Bfotool. (2026). Apa itu Pull Request dan Code Review?